Gratwanderung zwischen regulatorischer Notwendigkeit und ökonomischer Effizienz
Seit Januar 2018 liegt die verbindliche Mindestliquiditätsdeckungsquote bei 100 %. Die Bevorratung hochliquider Aktiva hat jedoch unmittelbare ökonomische Konsequenzen: Die geringere Rendite dieser Aktiva belastet die in der anhaltenden Niedrigzinsphase ohnehin eingeschränkte Ertragskraft von Finanzinstituten zusätzlich. Die Gratwanderung besteht darin, die LCR leicht oberhalb der Mindestquote zu steuern und diese jederzeit einzuhalten. Prüfungsberichte zeigen zudem die nachvollziehbare Erwartung der Aufsicht, dass eine höhere LCR-Volatilität auch ein höheres internes LCR-Limit bedingt.
Eine effiziente Steuerung der LCR setzt daher eine möglichst stabile LCR sowie eine hohe LCR-Prognosegüte voraus. Die Beurteilung der LCR-Volatilität muss dabei auch untermonatliche Effekte berücksichtigen, was nach unserer Erfahrung und insbesondere in vielen kleineren Häusern oft nur sehr eingeschränkt erfolgt. Die natürliche Volatilität der LCR hängt von dem institutsspezifischen Geschäftsmodell und der Produktstruktur sowie ‑gestaltung ab. In der Praxis lässt sich häufig beobachten, dass noch immer einige, insbesondere kleinere Institute, nur eine rudimentäre oder noch keine LCR-Prognose implementiert haben. Aber auch größere Institute haben teilweise erhebliche Probleme eine ausreichende Prognosegüte zu erreichen. Die Prognose der LCR mithilfe künstlicher Intelligenz (KI) ermöglicht eine signifikante Verbesserung der LCR-Prognosegüte und folglich der LCR-Steuerung.
Signifikanter Ertragsvorteil durch den Einsatz von KI bei der LCR-Prognose
Der Einsatz von KI für die LCR-Prognose bietet drei wesentliche Nutzenaspekte:
1) Ökonomischer Nutzen
Der primäre ökonomische Nutzen resultiert daraus, dass eine genauere LCR-Prognose die Wahl einer niedrigeren internen Ziel-LCR ermöglicht und zugleich die Einhaltung der Mindestliquiditätsdeckungsquote gewährleistet. Die Reduzierung des Bestands LCR-fähiger Aktiva ermöglicht renditestärkere Investitionen und die frühzeitige Initiierung von Steuerungsmaßnahmen. Ein längerer Planungshorizont erweitert das Universum möglicher Steuerungsinstrumente und generiert Kostenvorteile bei der Maßnahmenauswahl sowie ‑umsetzung.
2) SREP-Bewertung und regulatorische Anforderungen
Gemäß MaRisk[2] und ILAAP[3] sind Institute sowohl verpflichtet, Liquiditätsengpässe frühzeitig zu erkennen als auch deren Entwicklung zu prognostizieren. Der Einsatz von KI erhöht die Genauigkeit der LCR-Prognose, was wiederum die Aussteuerung der LCR gemäß des internen LCR-Limits ermöglicht, wodurch folglich die LCR-Volatilität sinkt. Beide Aspekte wirken somit positiv auf die normative Perspektive des ILAAP im Rahmen des SREP[4].

3) KI-Erfahrung als Wettbewerbsvorteil in der digitalen Transformation
Die Verwendung künstlicher Intelligenz ist ein wesentlicher Bestandteil der digitalen Transformation des Bankensektors. Zu diesem Ergebnis kommt auch die BaFin[5], die sich selbst zunehmend mit dem Thema auseinandersetzt und ein klares Interesse sowie Offenheit bezüglich unterschiedlichster Anwendungsgebiete signalisiert hat. Für Banken ist es daher wichtig, den Anschluss nicht zu verpassen und sich mit dem Thema künstliche Intelligenz auseinanderzusetzen. Dies kann nur anhand konkreter Anwendungsfälle gelingen. Frühzeitige Erfahrung im Einsatz von KI stellt absehbar einen wichtigen Wettbewerbsvorteil dar.
Um den ökonomischen Nutzen zu veranschaulichen, wurden die Ertragspotenziale anhand einer vereinfachten Beispielrechnung in Abbildung 1 approximiert.
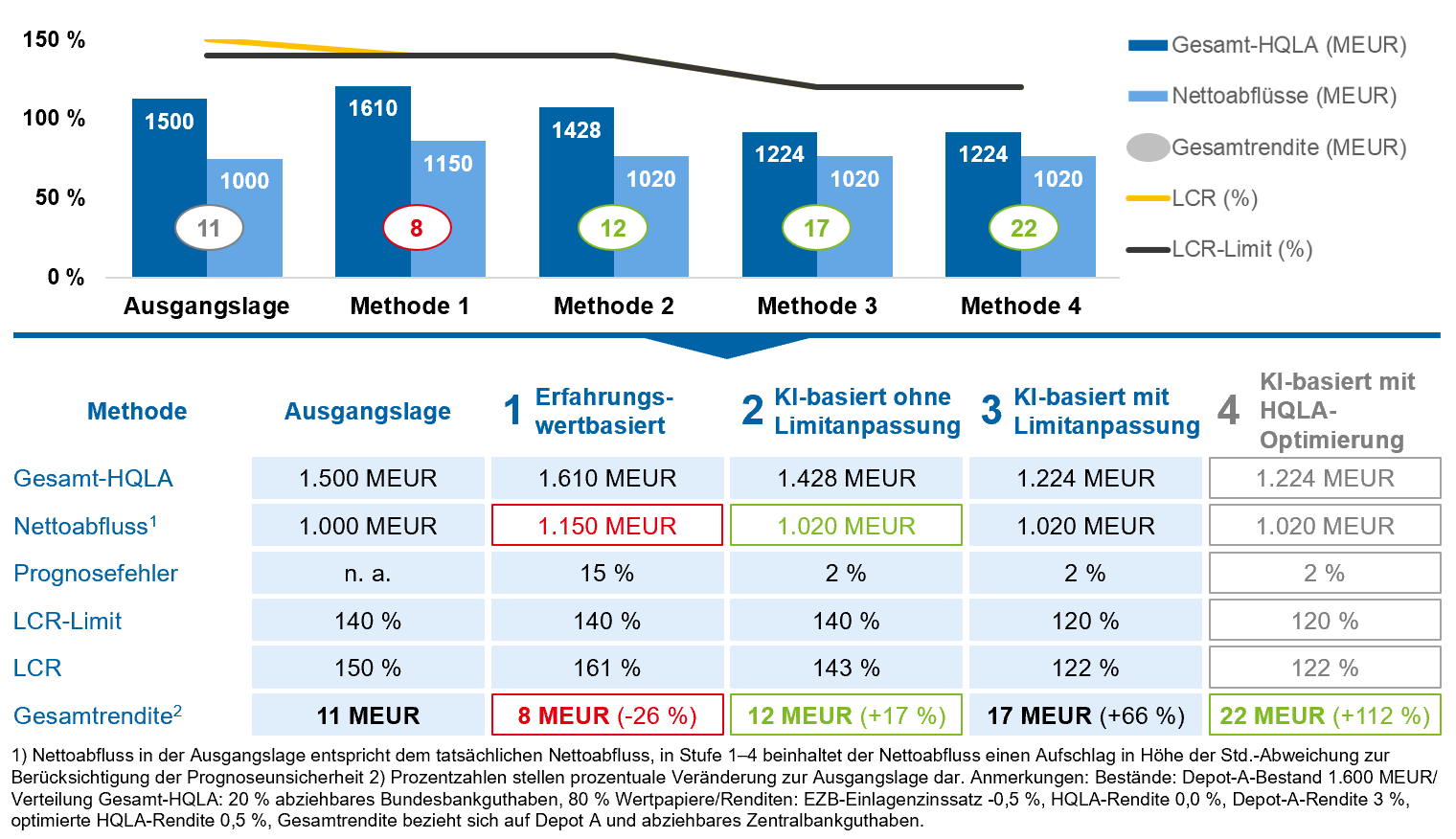 Abbildung 1: Ökonomischer Nutzen – Ertragspotenziale einer Musterbank
Abbildung 1: Ökonomischer Nutzen – Ertragspotenziale einer MusterbankIn der Ausgangssituation verfügt das Institut über keine LCR-Prognose, hat einen Depot-A-Bestand von 1,6 Mrd. EUR, liquide Aktiva i. H. v. 1,5 Mrd. EUR, ein internes LCR-Limit von 140 % und eine aktuelle LCR von 150 %. Die Gesamtrendite, d. h. die kombinierte Rendite aus Depot-A-Wertpapieren sowie abziehbaren Zentralbankreserven, liegt in der Ausgangssituation bei 11 Mio. EUR. Das Institut wendet nun einen erfahrungswertbasierten Ansatz an (Methode 1). Auf Basis historischer Daten wird ein Prognosefehler der erfahrungswertbasierten Schätzung der Nettozahlungsmittelabflüsse i. H. v. 15 % ermittelt. Um sicherzustellen, dass die Bank auch bei einem erwarteten Nettoabfluss von 115 % des aktuellen Nettoabflusses das interne LCR-Limit einhält, müssen 110 Mio. EUR zusätzliche liquide Aktiva vorgehalten werden. Hierdurch sinkt die Gesamtrendite auf nur noch 8 Mio. EUR.
Durch eine KI-gestützte LCR-Prognose gelingt es dem Institut, den Prognosefehler auf 2 % zu reduzieren. Es muss folglich nur noch mit einem erwarteten Nettoabfluss von 1,02 Mrd. EUR rechnen und entsprechend weniger liquide Aktiva vorhalten (Methode 2). Aus der Freisetzung der liquiden Aktiva resultiert eine um 17 % höhere Gesamtrendite. Da die Prognoseunsicherheit reduziert wurde, kann das Institut nun gegenüber der Aufsicht eine Senkung des internen LCR-Limits von 140 % auf 120 % nachvollziehbar begründen (Methode 3). Dies führt zu einem geringeren Bedarf hochliquider Aktiva und damit zu einer erneuten Reallokation hin zu renditestärkeren, nicht LCR-fähigen Aktiva, was zu einer weiteren Renditesteigerung führt.
Weiteres Optimierungspotenzial bietet die LCR-Pufferoptimierung (Methode 4) mittels KI. Hierbei kann einerseits die Pufferstruktur (Level 1, Level 2A, Level 2B) optimiert werden und andererseits die Auswahl der Aktiva je LCR-Level. In der Beispielrechnung erwarten wir hier eine konservative Steigerung der durchschnittlichen Portfoliorendite um einen halben Prozentpunkt, was in einer Erhöhung der Gesamtrendite auf 22 Mio. EUR resultiert.
Trotz des stark vereinfachten Beispiels liegen die Optimierungs- und Ertragspotenziale auf der Hand. Der erfolgreiche Einsatz von KI zur Optimierung von Prognosen (bspw. zur Modellierung von Sondertilgungen oder Vorfälligkeiten) wurde im Rahmen verschiedenster Projekte unter Beweis gestellt. Damit stellt die LCR-Prognose ein ideales Anwendungsgebiet für KI dar. Neben der reinen Prognose auf Basis der gewöhnlichen Geschäftstätigkeit, sollte die ideale Ziellösung zur LCR-Prognose zusätzlich auch die Möglichkeit beinhalten, LCR-Steuerungsmaßnahmen sowie Geschäfte mit einer erheblichen Auswirkung auf die LCR zu simulieren.
Vorgehensmodell als kritischer Erfolgsfaktor für KI-Anwendungen
Während die einfachsten Formen der KI darauf ausgerichtet sind, aus Daten und einem vorgegebenen Modell Parameter abzuleiten (bspw. Regressionsmodell), werden bei den komplexeren Modellen des Machine Learning und Deep Learning keine Regeln vorgegeben, sondern nur noch Daten, anhand derer die KI das Modell selbst ableitet. Wie aus Abbildung 2 ersichtlich ist, umfasst der Begriff „Künstliche Intelligenz“ u. a. alle Formen des maschinellen Lernens, die versuchen, menschliche Denkstrukturen abzubilden. Machine Learning und Deep Learning sind als Subkategorien von KI zu verstehen.
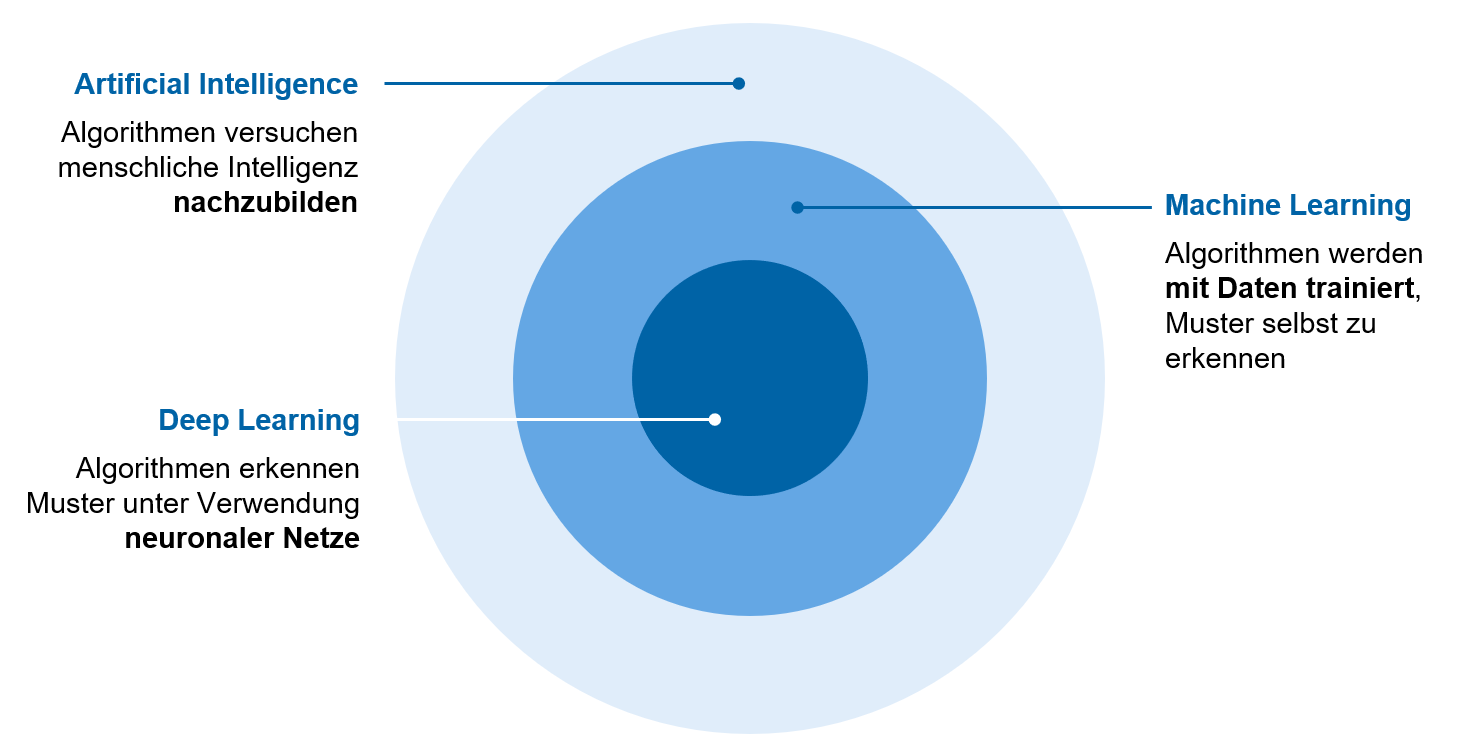 Abbildung 2: Klassifizierung von KI
Abbildung 2: Klassifizierung von KIEine weitere Klassifizierung von KI-Methoden resultiert aus der Art des „Lernproblems“. Während das Ziel bei Supervised-Learning-Methoden darin besteht, aus einem gegebenen Input einen vordefinierten Output (bspw. Wert, Kategorie o. Ä.) nach bestimmten Vorgaben zu generieren, liegt der Fokus von Unsupervised-Learning-Methoden auf dem Verstehen von Daten. So erfolgt bspw. bei der Clusterbildung keine vorherige Definition der Gruppen (siehe Beispiele in Abbildung 3).
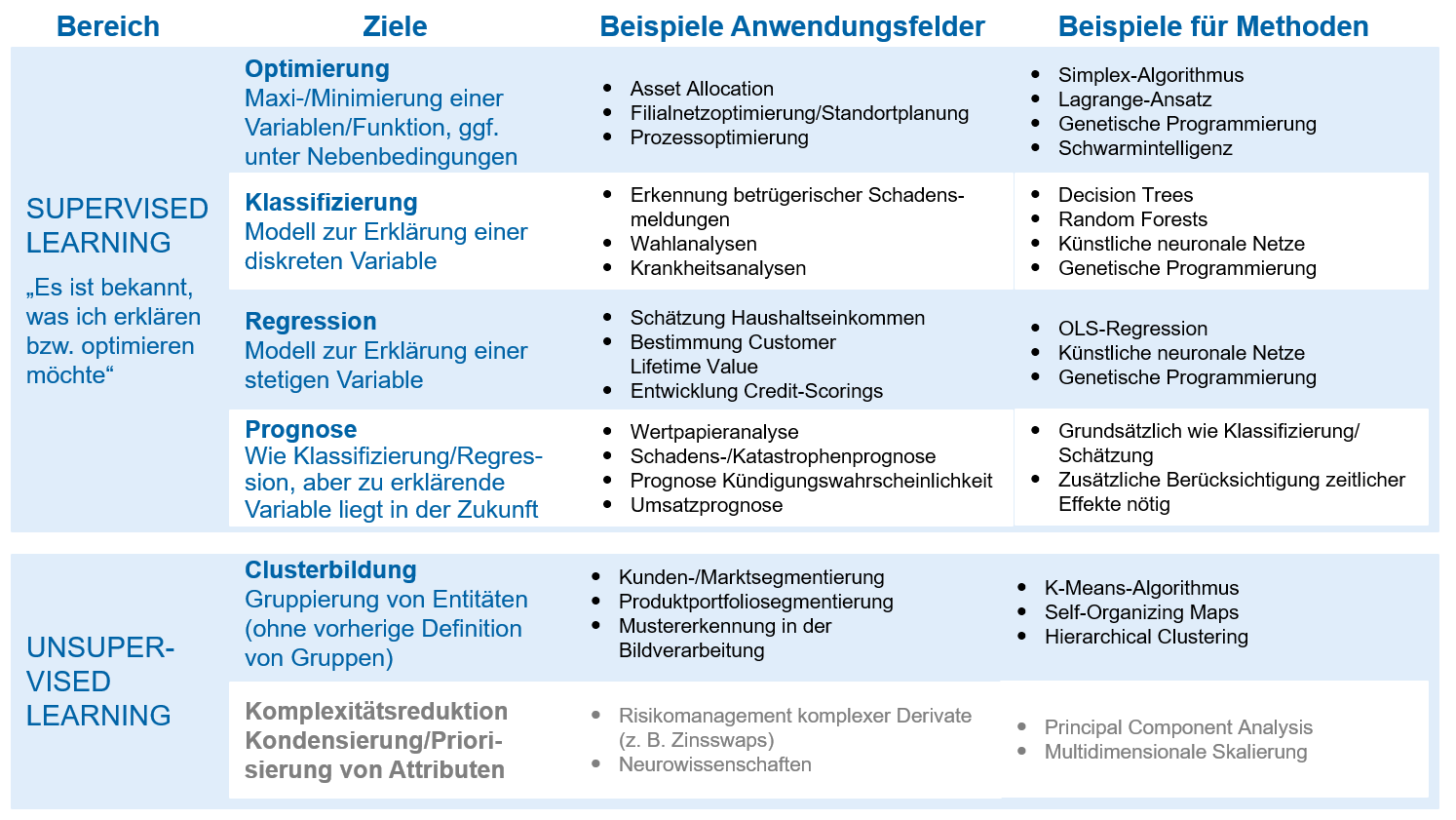 Abbildung 3: Weiterführende Klassifizierung von ML-Methoden
Abbildung 3: Weiterführende Klassifizierung von ML-MethodenBei der Entwicklung von KI-Anwendungen hat sich das zeb-Vorgehensmodell[6] bereits bewährt, mit dem schnell erste Erfolge beobachtbar sind. Dabei hat sich die enge fachliche Abgrenzung des Use-Case als ein wesentlicher Erfolgsfaktor herausgestellt. Anschließend werden Hypothesen bezüglich des Einflusses verschiedener Variablen auf die zukünftige Entwicklung der LCR gebildet. In Bezug auf die Rahmenbedingungen ist zudem zu prüfen, inwiefern erforderliche Daten in geeigneter Datenstruktur vorliegen und auch juristisch verwertbar sind. Auf Basis der ausgewählten Daten werden die geeigneten Methoden eingegrenzt und anhand der konkreten Methodenergebnisse im Rahmen eines Beauty Contest verglichen. Als Bewertungsreferenz für die Prognosegüte werden entweder historische Daten verwendet oder die Ergebnisse eines bereits bestehenden Ansatzes. Neben der Prognosegüte sind Kriterien wie Nachvollziehbarkeit, Modellbedienbarkeit und Implementierungsaufwand zu berücksichtigen.
Institutsspezifische Evaluation des LCR-Prognoseansatzes notwendig
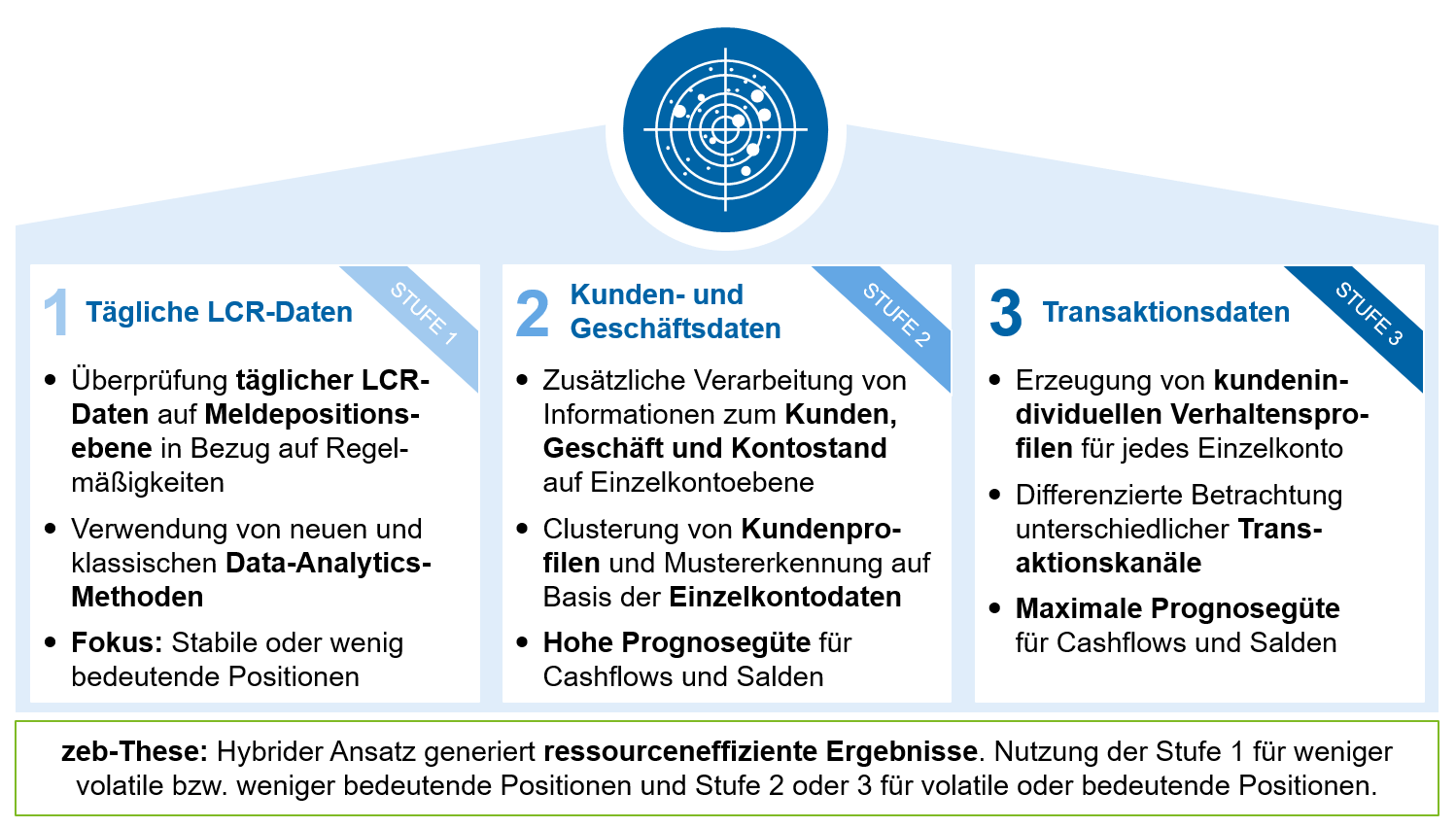 Abbildung 4: Stufen der LCR-Prognose
Abbildung 4: Stufen der LCR-PrognoseUnter Berücksichtigung von institutsspezifischen Anforderungen, der Art und Komplexität des Geschäftsmodells sowie der verfügbaren Ressourcen sind verschiedene Stufen der LCR-Prognose mit KI denkbar. Die Stufen unterscheiden sich hinsichtlich ihrer Datengranularität sowie des verwendeten Modellierungsansatzes. Abbildung 4 zeigt einen Überblick zu den verschiedenen Stufen der LCR-Prognose, wobei die nachfolgende Stufe immer auch die Analyse der Daten der vorhergehenden Stufe(n) beinhaltet.
Stufe 1: Tägliche LCR-Daten
Eine grundlegende LCR-Prognose kann i. d. R. bereits auf Basis von aufsichtsrechtlichen Meldeformularen erstellt werden. Dabei werden tägliche Werte der Meldepositionen aus den Meldeformularen C 72.00 bis C 76.00 für einen erweiterten Zeithorizont, bspw. drei Jahre, benötigt. Sofern verfügbar, kann die Datenbasis durch Einzelgeschäftsnachweise erweitert werden, um die Prognosegüte zu erhöhen.
Eine Analyse der Zeitreihen von einzelnen Meldepositionen kann bspw. zyklische Muster identifizieren. Saisonale Schwankungen sind durch Gesetzmäßigkeiten bedingt, wie z. B. der zunehmende Konsum in der Weihnachtszeit. Weitere Muster ergeben sich bspw. durch monatliche Rhythmen für Gehaltseingänge oder Mietzahlungen.
Zur Identifikation der Regelmäßigkeiten stehen neben klassischen Methoden, wie z. B. lineare Regressionen, auch moderne Data-Analytics-Methoden zur Verfügung. Moderne Verfahren können im Vergleich zu herkömmlichen Methoden insbesondere saisonale Effekte besser erkennen. Allerdings gilt, dass die Prognosegüte eines Modells stark von den Eingabedaten abhängt. Da diese in Stufe 1 hochaggregiert vorliegen, ist der Vorteil im Vergleich zu klassischen Methoden häufig limitiert.
Stufe 2: Erweiterung um Kunden-, Konto- und Marktdaten
Zur Verbesserung der LCR-Prognosegüte werden in Stufe 2 zusätzlich Kunden- (Alter, Einkommen, Kreditscores etc.), Konto- (Salden, Limite etc.) und Marktdaten (Zinsen, BIP etc.) herangezogen.
Kunden- und Kontoinformationen ermöglichen es, Kundenprofile auf Basis von Verhaltensattributen abzuleiten und Kunden in homogene Cluster einzuteilen. Das Erlernen der üblichen Cashflowprofile dieser Cluster kann die Prognosegenauigkeit signifikant erhöhen. Zudem können zusätzlich Migrationen zwischen Kundenkategorien KMU-Retail und KMU-Wholesale antizipiert werden. Neben bankinternen Daten können auch externe Marktdaten zur Analyse hinzugezogen werden. So stellen beispielsweise das Zinsniveau, Zinsstrukturkurven oder auch das BIP relevante Einflussfaktoren dar und ermöglichen eine weitere Verbesserung der LCR-Prognosegüte.
Stufe 3: Erweiterung um Transaktionsdaten
In Stufe 3 werden zusätzlich Transaktionsdaten in der Analyse berücksichtigt. Beispielsweise sind hier Informationen zum Transaktionskanal (Kreditkarte, EC-Karte, Lastschrift etc.), zur Kategorie der Zahlung (Lohn/Gehalt, Hypothek, Konsumausgaben etc.) oder Kundenkontaktinformationen wie ein Kreditangebot von Interesse. Die Transaktionsdaten können mithilfe von maschinellem Lernen kategorisiert werden (bspw. Zahlungsmuster), wodurch Änderungen im Kundenverhalten erkannt und antizipiert werden können. Im Gegensatz zur Stufe 2 wird das Modell hierbei auf Einzelkundenebene trainiert. Somit werden Salden- und Cashflowvorhersagen je Einzelkonto möglich und eine maximale Prognosegüte erreicht.
Stufe 3 stellt nicht per se das optimale Zielbild für die LCR-Prognose dar. Vielmehr empfiehlt zeb einen hybriden Ansatz, der die Vor- und Nachteile der verschiedenen Stufen optimal und ressourceneffizient ausbalanciert. Die Auswahl der Granularitätsebene ist im Wesentlichen durch Institutsspezifika sowie die Volatilität und Bedeutung der einzelnen LCR-Positionen determiniert.
LCR-Steuerung mithilfe KI-gestützter LCR-Prognose stellt Kosten- und Wettbewerbsvorteil dar
Die KI-gestützte LCR-Prognose ermöglicht Banken die Realisierung von signifikanten Ertragspotenzialen und ein deutlich verbessertes Risikomanagement. Eine automatisierte LCR-Prognose entlastet zudem Risikomanagementressourcen und ist in hohem Maße flexibel. Neben der Einbindung historischer Daten kann die LCR-Prognose auch durch Szenariodaten ergänzt werden, um bisher nicht beobachtete Entwicklungen (Planannahmen, Black-Swan-Events etc.) zu simulieren. KI-Use-Cases wie dieser stellen einen wesentlichen Bestandteil der digitalen Transformation sowie eine wichtige Grundlage für die künftige Wettbewerbsfähigkeit von Banken dar.









