Anwendung und Funktionsweise der automatischen Textzusammenfassung
In diesem Artikel zeigen wir auf, wie wir verschiedene ML-/NLP-Technologien für die automatische Textzusammenfassung miteinander kombiniert haben, einschließlich Distilled-Transformer-Modelle und Reinforced Learning mithilfe von Expertenfeedback. Unser Prototyp ist eine Responsible-AI-Architekturlösung auf einem Kubernetes-Cluster in der Cloud, der Banken und Aufsichtsbehörden heute schon zugutekommen könnte.
Anwendungsgebiete der domänenspezifischen automatischen Textzusammenfassung
In einem früheren BankingHub-Artikel haben unsere Kolleg:innen auf die Flut umfangreicher und komplexer regulatorischer Veröffentlichungen hingewiesen, die mit großem Aufwand gelesen und ausgewertet werden müssen.
Die Anwendungsgebiete beschränken sich allerdings nicht nur auf das Meldewesen; manuelle Zusammenfassungen werden häufig auch im Vertrieb (z. B. beim Kundenreporting) und in Rechtsabteilungen (z. B. für Verträge) erstellt. Wir haben geprüft, wie mithilfe neuer Technologien wie der automatischen Textzusammenfassung der manuelle Workload reduziert werden kann.
Wie funktioniert die automatische Textzusammenfassung?
Die automatische Textzusammenfassung (Automatic Text Summarization, ATS) ist ein Teilbereich der natürlichen Sprachverarbeitung (Natural Language Processing, NLP), bei dem der Inhalt von Dokumenten in komprimierter Form wiedergegeben wird. Aus dem Input, der ein oder mehrere Dokumente umfassen kann, werden als Output extraktive bzw. abstraktive Zusammenfassungen (Awajan, 2020) für allgemeine abfragebasierte oder domänenspezifische Zwecke erstellt (Chauhan, 2018). Extraktive Zusammenfassungen speisen sich ausschließlich aus Sätzen, die so auch im Input-Text vorkommen. Abstraktive Zusammenfassungen sind etwas anspruchsvoller: Bei diesen muss die KI eigenständig kohärente Sätze bilden.
Für unsere Cloud-native Lösung zur automatischen Textzusammenfassung haben wir mangels passender Trainingsdaten einen Zero-Shot-Lernansatz[1] verwendet. Unsere Erfahrungen mit dieser Anwendung haben wir in diesem Artikel zusammengefasst. Unsere Untersuchung konzentrierte sich dabei auf domänenspezifische Themen wie „Qualität von Vermögenswerten“, „Kreditvergabe“, „Pandemie“ und „Klimarisiken“, die zum Untersuchungszeitpunkt besonders relevant waren.
Wie effektiv sind die NLP-Modelle für die Textzusammenfassung?
Transfer-Learning (Fulgosi, 1976) ist eine gängige Praxis im Bereich ML/NLP, bei der die zugrunde liegenden Sprachmodelle nicht von Grund auf neu entwickelt werden müssen. Stattdessen verwendet man Modelle, die für ähnliche Anwendungen vortrainiert wurden. Derzeit fokussiert sich die Forschung im Bereich NLP auf tiefe neuronale Netze, die als große Sprachmodelle (Large Language Models, LLM) für das Transfer-Learning zum Einsatz kommen.
Zu den vielversprechendsten vortrainierten Modellen für die Textzusammenfassung gehören:
Obwohl große Sprachmodelle derzeit im Rampenlicht stehen, ist die Größe des Modells nur einer von vielen Faktoren, die die Effektivität eines NLP-Modells bestimmen. Weitere Faktoren wie die Qualität und Größe der Trainingsdaten, die Modellarchitektur, das Pre-Training und Fine-Tuning, die Domänenspezifität, die Komplexität des Modells, die Hyperparameter-Abstimmung, die Bewertungsmetriken, die Rechenressourcen und heutzutage auch ethische Aspekte spielen eine wichtige Rolle.
Größere Modelle wie GPT-4 zeigen in Experimenten beeindruckende Leistungen. Jedoch können auch kleinere Modelle wie Alpaca[7] und verschiedene Distilled-Transformer-Modelle ein vergleichbares Maß an Genauigkeit erzielen. Durch ihre geringere Größe ist das Deployment von Alpaca oder DistilBERT[8] besonders praktisch, da sie sogar auf IoT-Edge-Geräten wie Mobiltelefonen oder Raspberry Pi einsatzfähig sind.
Für die Verarbeitung regulatorischer Anforderungen benötigen wir eine domänenspezifische/abfragebasierte, Textzusammenfassung eines einzelnen Dokuments in mehreren Sätzen. Obwohl es auf dem Markt bereits vielversprechende Lösungen gibt, stehen wir immer noch vor einigen Herausforderungen.
Wo liegen die Herausforderungen bei der Nutzung vortrainierter Modelle?
Langes Dokument: Vortrainierte Modelle basieren auf einer seq2seq-Encoder-Decoder-Architektur, was in der Praxis bedeutet, dass der Text in einen Vektor fester Länge komprimiert werden muss. Dadurch ist die Verarbeitungskapazität der meisten Transformer auf 512 bzw. 1.024 Token beschränkt.[9]
Dadurch kommen einige der verfügbaren vortrainierten Modelle für unsere geplante Verwendung nicht infrage. Mit dem vortrainierten Modell, das auf Bidirectional Encoder Representations from Transformers (BERT) (McCormick, 2020) basiert, wurden mehrere State-of-the-Art (SOTA) Transformer getestet, darunter
- Modelle auf Basis von Pre-training with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence (PEGASUS) (Jingquing Zhang, 2019)
- BART von Meta AI (Facebook), ein Entrauschungs-Autoencoder, der sowohl Elemente von BERT als auch von GPT-3 enthält
- Text-To-Text-Transfer-Transformer (T5)
Attention-Mechanismen zur Schwerpunktsetzung: Die auf dem Markt verfügbaren generischen Standardlösungen zur Textzusammenfassung ermöglichen es nicht, im Vorfeld den Fokus auf bestimmte Themen zu richten. Die daraus resultierenden Zusammenfassungen sind sehr allgemein gehalten, als ob ein Mensch das Dokument nur überflogen hätte. Je nachdem, auf welches Thema das Augenmerk gelegt wird, z. B. Covid-19, Umwelt oder Recht, würden wir jedoch unterschiedliche Zusammenfassungen desselben Dokuments erhalten. Daher können wir für themenspezifische Zusammenfassungen keine generisch vortrainierten Modelle verwenden.
Bewertungskriterien: Die SOTA-Modelle verwenden ROUGE[10] und BLEU[11] zur Bewertung der Zusammenfassungsqualität (Fabbri et al. 2021). Das Problem besteht darin, dass ROUGE und BLEU nicht differenzierbare Funktionen sind. Daher können sie nicht als Optimierungsfunktion für Back-Propagation-basierte Deep-Learning-Netze verwendet werden, um automatisch zu lernen, d. h. die Parameter anzupassen. Aus diesem Grund werden andere Metriken wie RMSE zur Optimierung herangezogen. Aber eine Optimierung anhand der RMSE-Kriterien kann jedoch zu schlechten ROUGE- und BLEU-Ergebnissen führen.
Wie funktioniert unser Algorithmus für die Textzusammenfasung im Detail?
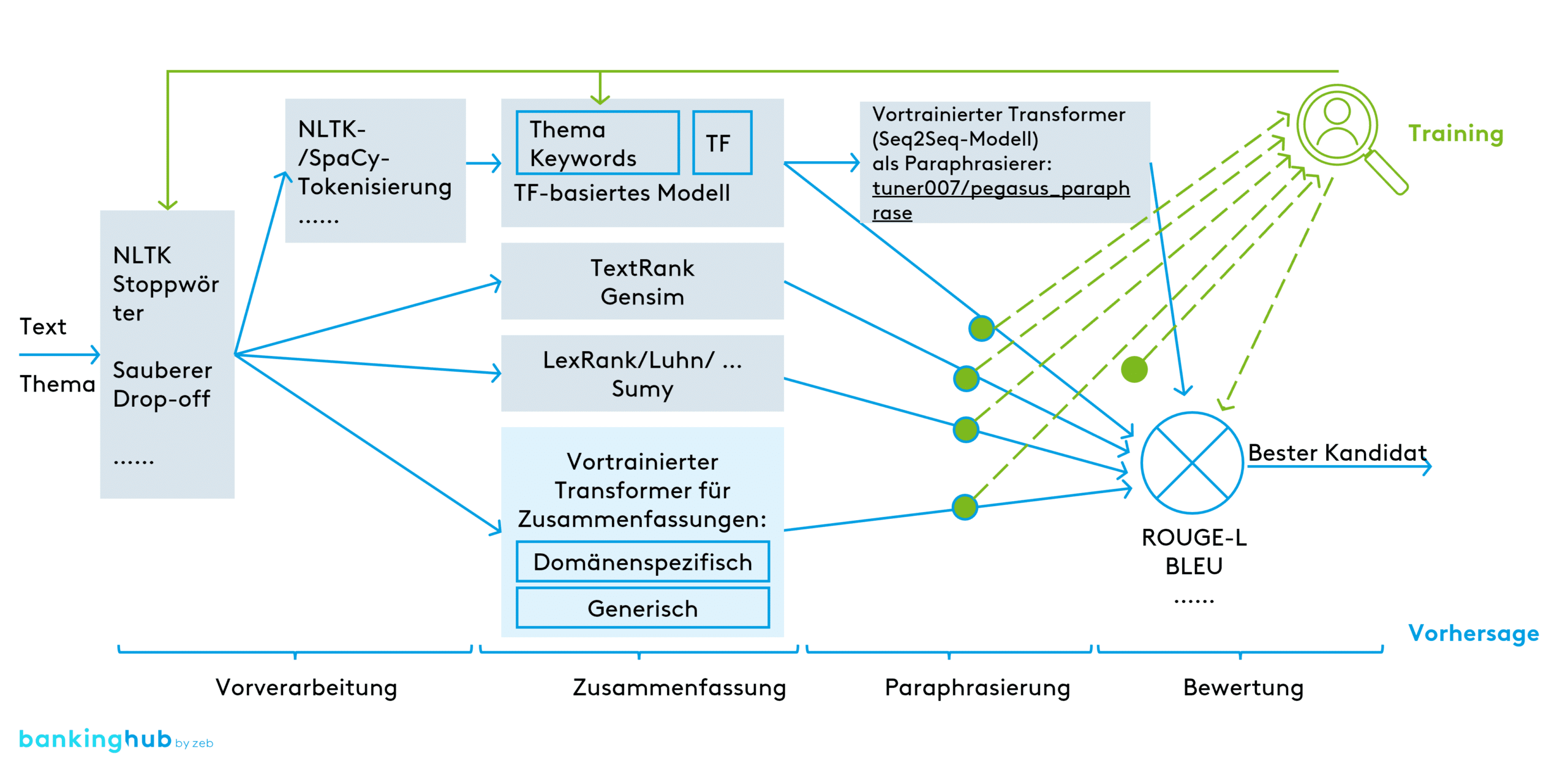
Wie in Abbildung 1 dargestellt, verwenden wir eine kombinierte Architektur, um gleichzeitig ein extraktives Zusammenfassungsmodell auf der Grundlage von Termfrequenz (TF), TextRank (TR) und LexRank (LR) auszuführen, um drei Zusammenfassungs-Kandidaten zu erhalten. Wir verwenden die TF-Ausgabe als Input für das Seq2Seq-Modell (Sutskever et. al, 2014). Der Encoder nimmt die extraktive Zusammenfassung als Eingabe und ‚versteht‘ dies in der Form von Vektoren. Der Decoder generiert kohärente und semantisch äquivalente Paraphrasierungen als endgültige Ausgabe.
Auf Grundlage der Bewertungsmetrik von ROUGE-L[12] und BLEU wählen wir das Modell mit den besten Ergebnissen aus.
- Der Vorteil der extraktiven Methoden (TF, TR, LR) ist, dass sie die Zusammenfassung schneller ohne Beschränkung der Eingabegröße generieren. Dabei werden jedoch nur die wichtigsten Sätze aus dem Dokument selektiert.
- Abstraktive Methoden (Seq2Seq) sind fortschrittlicher und verwenden ein vorab trainiertes neuronales Netz, um das Dokument zu „verstehen“ und auf dieser Grundlage neue Sätze zu generieren. Sie weisen jedoch die gleichen Probleme auf, die wir bereits für vortrainierte Modelle aufgeführt haben.
Unsere Architektur nutzt die Vorteile beider Ansätze und gleicht dabei ihre Nachteile aus.
Als Paraphrasierer (oben rechts in Abbildung 1) haben wir das vortrainierte Modell für die Absatzbildung ausgewählt, das auf dem leistungsfähigsten PEGASUS-Modell basiert.
- „tuner007/pegasus_paraphrase“
Für das Erstellen der Zusammenfassungen haben wir als Kandidaten (unten in Abbildung 1) verschiedene Transformer (vortrainierte Modelle) der Plattform huggingface[13] getestet.
Für Themen wie „Qualität von Vermögenswerten“ und „Kreditvergabe“ wurden die domänenspezifischen Transformer
- „human-centered-summarization/financial-summarization-pegasus“
- „nsi319/legal-pegasus“
verwendet, da diese anhand spezifischer Datensätze aus den Bereichen Finanzen und Recht trainiert wurden.
Für die restlichen Themen wie „Pandemie“ und „Klimarisiken“ wurden die allgemeinen Transformer
- „google/pegasus-xsum“
- „facebook/bart-large-cnn“
eingesetzt, die anhand allgemeiner Nachrichtenbeiträge trainiert wurden.
In unseren Experimenten konnten GPT-2 und T5 keine großen Dokumente verarbeiten, während sich in den Zusammenfassungen von BigBirdPegasus Sätze wiederholten, weshalb diese Modelle für abstraktive Zusammenfassungen ungeeignet sind. Daher haben wir sie nicht verwendet.
Wir haben mit Meldewesenexpert:innen zusammengearbeitet, um die generierten Zusammenfassungen zu bewerten und die Keywords für die Vorverarbeitung sowie die Algorithmusparameter auf der Grundlage ihres Feedbacks mithilfe von Modell-Engineering zu optimieren. Dies stellt eine Form des „Reinforced Learnings“ mit Experteninput dar.
Für künftige Experimente kann alternativ auch die hierarchische Zusammenfassung verwendet werden. Dabei wird das Input-Dokument in kleinere Unterdokumente unterteilt, für die jeweils eine Zusammenfassung generiert wird. Die einzelnen Zusammenfassungen werden dann im finalen Output zusammengeführt.
Eine weiterer zukünftiger Ansatz besteht darin, neuere vorhandene LLM-Modelle anhand eines Datensatzes mit großen Dokumenten einem Feintuning zu unterziehen und somit ihre Leistung zu verbessern. Zum Beispiel könnten wir ein fine-tuned open-source LLM GPT-J als fundamentales Modell nehmen. Mit Hilfe von speziellen Pipelines, z.B. Python LangChain[14] kann eine Anonymisierungsfilter-Engine, z. B. Presidio[15], integriert werden. Somit kann wiederum der emergente Moment dieser LLMs bei unseren spezifischen geschützten Daten ermittelt werden
Was haben wir mit unserem Algorithmus zur Textzusammenfassung erreicht?
Wir haben die Herausforderungen gemeistert, indem wir verschiedene Heuristiken zu einer Lösung kombiniert haben, die unterschiedliche Vorteile in sich vereint.
- Unser Ansatz kann lange Dokumente verarbeiten, sogar solche mit mehr als 100.000 Token. Dies wird durch den Einsatz von traditionellen Methoden wie TF, LexRank und TextRank kombiniert mit einem Transformer als Paraphraser ermöglicht. Die meisten SOTA-Transformer für Zusammenfassungen sind hingegen auf 1.024 Token beschränkt. GPT-3 ist auf 2048 Token begrenzt.
- Unsere oben beschriebene Lösungsarchitektur ermöglicht das Zusammenfassen großer Dokumente innerhalb von Sekunden. Andere SOTA-Lösungen wie GPT-3 hingegen benötigen dafür mehrere Minuten.
- Im Gegensatz zu den SOTA-Lösungen, die enorme Mengen an Trainingsdaten und im Falle von GPT-3 mindestens eine One-Shot-Datengrundlage benötigen, haben wir einen Zero-Shot-Trainingsansatz verwendet, der auf vortrainierten Transformern basiert.
- Als Maßstab haben wir die gleichen Metriken (ROUGE und BLEU) sowohl für die Optimierung als auch für die Bewertung verwendet und dabei eine ROUGE-Bewertung von über 50 % erzielt. Unsere Lösung kann also mit den SOTA-Modellen mithalten.[16]
In diesem Artikel haben wir eine Möglichkeit aufgezeigt, branchenspezifische und wirtschaftliche Lösungen für die Textzusammenfassung im Finanzdienstleistungssektor zu entwickeln, und das unabhängig von großen öffentlich zugänglichen Sprachmodellen wie GPT. Finanzdienstleister sollten die rasante Entwicklung in diesem Bereich im Auge behalten, um Effizienzpotenziale zu heben.







