Data Lakehouse kombiniert Data Warehouse und Data Lake
Der Begriff „Data Lakehouse“ setzt sich aus den bekannten Konzepten Data Warehouse und Data Lake zusammen und beschreibt einen Ansatz, der die Vorteile von Data Warehouse und Data Lake in einer gemeinsamen Plattform kombinieren soll.
Architekturkonzept Data Warehouse
Das klassische Data Warehouse wird für konkrete Anwendungen entworfen und entwickelt – z. B. Meldewesen, Risikomanagement oder Vertriebssteuerung. Es wird anhand der für diese Anwendungen erhobenen Anforderungen modelliert, und entsprechende Quelldaten werden angebunden.
Die Daten werden i. d. R. qualitätsgesichert, transformiert und strukturiert in einem Zielmodell abgelegt und dort historisiert. Die Eingangsdaten sind üblicherweise flüchtig und werden nach der Verarbeitung gelöscht. Mit dem Zielmodell wird „eine Wahrheit“ („single point of truth“) geschaffen. Datenhaltung und Datentransformationen erfolgen in den meisten Instituten in relationalen Datenbanken.
Betrieb sowie Ausbau eines Data Warehouse sind in der Praxis häufig mit hohem Aufwand bei der Datenintegration und -harmonisierung sowie hohen Hardware- und Speicherkosten verbunden.
Architekturkonzept Data Lake
Durch die zunehmende Datenflut und steigende Anforderungen hinsichtlich der Datennutzung (Umfang, Struktur, zeitliche Verfügbarkeit/Latenz) – beispielsweise durch KI-Anwendungen – haben sich Data Lakes etabliert. Beim Entwurf eines Data Lake liegen i. d. R. weniger konkrete Anwendungsfälle vor.
Quelldaten werden nicht nur anhand konkreter Use Cases erhoben, sondern Daten werden „bevorratet“, um früher oder später verwendet zu werden. Alle denkbaren Daten (auch Bilder, Videos, Kommunikation …) werden angebunden und in der „landing zone“ abgelegt sowie historisiert.
Aufbereitung und Transformation der Rohdaten erfolgen erst bei der Verwendung für bestimmte Anwendungsfälle („schema-on-read“-Konzept). Abnehmer der aufbereiteten und transformierten Daten sind häufig moderne „advanced analytics“-Methoden (KI).
Vorteile: Data Warehouse vs. Data Lake
Sowohl Data Warehouse als auch Data Lake haben ihre eigenen Vorteile:
Vorteile von Data Warehouse
- Die Daten liegen in strukturierter, normierter und konsumorientierter Form vor. Der/Die Fachanwender/-in kann davon ausgehen, dass gleiche Daten verschiedener Quellsysteme im Zieldatenmodell harmonisiert und historisiert sind.
- Die Daten sind in der Regel qualitätsgesichert.
- Verschiedene Techniken wie Caching oder Indexing erlauben einen performanten Zugriff.
- Die Datenbankmanagementsysteme stellen Transaktionssicherheit her („ACID“-Transaktionen).
- Typische Data-Warehouse-Systeme verfügen über fein einstellbare Sicherheits- und Governance-Features wie Zugriffskontrolle und Audit-Logging.
Vorteile von Data Lake
- Strukturierte, semistrukturierte und unstrukturierte Daten können ohne (großen) Modellierungs- und Transformationsaufwand gesammelt und persistiert werden.
- Anwenderinnen und Anwender können direkt auf die Rohdaten zugreifen und diese je nach Bedarf verarbeiten.
- Das Filesystem eines Data Lake kann auf skalierbarer und kostengünstiger Speicherhardware/‑software implementiert werden.
- Gut konzipierte Lösungen sind skalierbar und optimalerweise „cloud native“ aufgebaut, sodass für den Betrieb relativ kostengünstige und performanceoptimierte Optionen bestehen.
- Die Etablierung von vielen mächtigen Open-Source-Werkzeugen verringert Kosten und ermöglicht schnellere Softwareupdates.
Mehrwerte des Data Lakehouse
Das Data-Lakehouse-Konzept kombiniert viele Vorteile und verspricht darüber hinaus dedizierte Mehrwerte.
Um die Vorteile beider Plattformen auszunutzen, verwenden einige FDL eine mehrstufige Architektur aus beiden Ansätzen, d. h., dass sich sowohl Data Warehouse als auch Data Lake im Einsatz befinden.
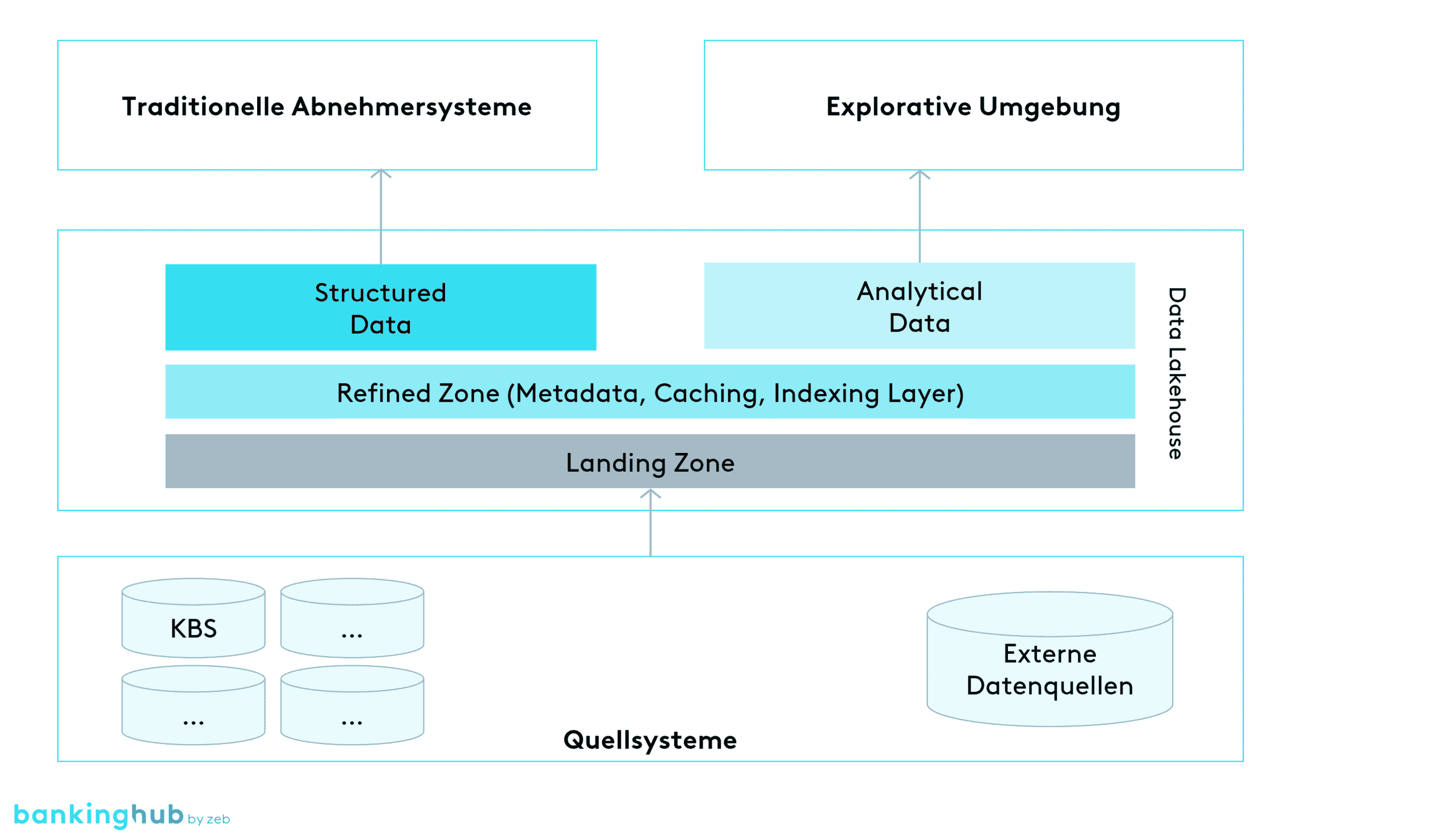
Der Data-Lakehouse-Ansatz verspricht nun im Gegensatz zu separaten Systemen eine Kombination von Data Warehouse und Data Lake auf einer gemeinsamen Plattform.
Vereinfacht gesprochen wird im Data Lakehouse eine Sammlung und Historisierung von Rohdaten organisiert. Darüber befindet sich eine harmonisierte, qualitätsgesicherte und historisierte Schicht (häufig als „refined zone“ bezeichnet), welche inhaltlich dem Kerndatenmodell eines Data Warehouse ähnelt. Von dieser Schicht werden die traditionellen Applikationen, Rechenkerne und Reportings versorgt. Zusätzlich dort enthalten sind die Daten für produktive Data Analytics Use Cases, welche auch hinreichend qualitätsgesichert und „under governance“ sein müssen. Die explorativen Funktionen der Data-Analytics-Disziplin können auf Daten der Rohdatenschicht und der „refined zone“ zugreifen.
Zusätzliche Potenziale des Data Lakehouse
Neben den dedizierten Vorteilen von Data Warehouse und Data Lake können dadurch zusätzliche Potenziale gehoben werden:
Einheitlicheres Toolkit: Für den separaten Betrieb von getrennten Data-Warehouse- und Data-Lake-Plattformen wird eine Reihe verschiedener Tools und Techniken – teilweise für ähnliche Aufgaben – eingesetzt. Der Data-Lakehouse-Ansatz bietet das Potenzial, den so entstandenen „Toolzoo“ zu verkleinern, d. h. Lizenzkosten einzusparen und die Anforderungen an die toolspezifischen Kenntnisse der Mitarbeitenden zu reduzieren.
Reduzierung redundanter Datenhaltung und Business-Logiken: Je nach betrachtetem Anwendungsfall werden Daten teilweise redundant in Data Warehouse und Data Lake gespeichert und in Verbindung mit doppelten Logiken angelegt. Mit einem Data-Lakehouse-Ansatz kann diese Redundanz vermieden werden.
Vereinfachung der Data Governance: Mit der Harmonisierung in einem Data Lakehouse wird die Anzahl der Systeme und die redundante Datenhaltung reduziert. Dies kann eine Vereinfachung der Data Governance ermöglichen, da Systemgrenzen abgebaut und Konflikte im Data Ownership zwischen redundanten Daten vermieden werden.
Reduzierung von ETL-Strecken: In einer mehrstufigen Architektur aus Data Warehouse und Data Lake müssen oftmals Daten zwischen beiden Plattformen ausgetauscht werden. In einem Data Lakehouse entfällt der Datenaustausch zwischen Plattformen, was wiederum Kosten und Komplexität senken kann.
Hardware-/Betriebskosten: Der Ansatz hat hohes Potenzial zur signifikanten Kostenreduktion (Hardware/Betrieb), insbesondere sofern Design und Implementierung „cloud native“ erfolgen. Er bietet damit einhergehend hohe Flexibilität für den weiteren Ausbau und die Nutzung von „Rechenlast on demand“.
Lassen Sie sich nicht täuschen
Trotz vieler Vorteile sprechen einige Argumente gegen eine neue Datenarchitektur – doch lassen Sie sich nicht täuschen!
Die ganzheitliche Betrachtung der genannten Vorteile und Chancen, die sich durch das Data-Lakehouse-Konzept eröffnen, müssten alle überzeugen, die sich mit Datenarchitekturen und deren Effizienz beschäftigen. Auf der anderen Seite können natürlich selbst gute Konzepte schlecht umgesetzt werden.
Viele Häuser stehen wie eingangs erwähnt vor dem Problem einer historisch gewachsenen Datenarchitektur mit existierenden Data Warehouses und ggf. auch schon etablierten Data Lakes. Hier mag der erste Reflex vieler Entscheider/-innen, Architektinnen und Architekten sowie Verantwortlichen für Change und Run sein, die bestehende Architektur lieber nicht infrage zu stellen, d. h. dem „unconscious status quo bias“ zu erliegen.
Bestätigt wird diese Tendenz durch eine Anzahl „guter“ Argumente, welche gegen eine neue Datenarchitektur sprechen: Die Risiken sind zu hoch, der Umbau kostet zu viel Geld, in die bestehende Lösung sind bereits große Investitionen geflossen, das Know-how in der Belegschaft ist dafür nicht ausgelegt oder zur Unterstützung der Business-Strategie ist die bestehende Lösung ausreichend, zumal die IT-Strategie ein Data Lakehouse ja gar nicht erwähnt.
Obige Einwände (und die Liste ist nicht abschließend) sind sicherlich zum aktuellen Zeitpunkt für viele Häuser zutreffend. Gleichzeitig müssen Führungskräfte und Entscheider/-innen ständig hinterfragen, wie sie ihr Unternehmen bzw. ihren Verantwortungsbereich fit halten oder fit für die Zukunft gestalten können. Vor diesem Hintergrund sind die genannten Einwände zu rationalisieren und gegen ihre Opportunitätskosten aufzuwiegen. Es darf nicht passieren, dass nötige Veränderungen abgelehnt und wichtige IT-Trends verschlafen werden.
Fazit: Data Lakehouse
Überprüfen Sie Ihre IT-Strategie und setzen Sie die richtigen Leitplanken!
Das Repertoire an Floskeln bezüglich der sich stetig schneller entwickelnden Anforderungen und der ständig wachsenden Möglichkeiten der Digitalisierung möchten wir an dieser Stelle nicht erweitern. Viele Betriebe definieren bereits eine Geschäftsstrategie und damit einhergehend ihre IT-Strategie, beides muss regelmäßig überprüft und adjustiert werden. Stellt man dabei die aktuellen Fähigkeiten der eigenen IT-Architektur den antizipierten zukünftigen Anforderungen der Business-Seite (oder der Aufsicht) gegenüber, so werden viele Häuser nach möglichen mittel- und kurzfristigen Lösungen suchen müssen. Für den Bereich der dispositiven Datenarchitektur der Finanzdienstleister dürfte ein Data Lakehouse Teil der Lösung eines „fit for future“ sein.
Natürlich stellt sich dann die Frage nach dem individuellen konkreten Vorgehen. Ein „Wegwerfen und Neubauen“ ist unseren Erfahrungen nach in der Regel nicht der richtige Weg, insbesondere aufgrund der hohen Kosten und Risiken, die damit einhergehen. Bei Fokussierung der Fragestellung können stattdessen schnell unterschiedliche Maßnahmen gefunden werden, die eine sukzessive Entwicklung in Richtung des Zielbilds ermöglichen.




