Aber was wird unter Big Data verstanden?
Unter Big Data versteht man vor allem die zeitnahe Erfassung, Verarbeitung und Auswertung von sehr großen Datenvolumina, welche oft in unterschiedlichen Formaten vorliegen. Dieser Artikel stellt fachliche Anwendungsbeispiele von Big Data dar und zeigt den Mehrwert mit dem Fokus auf die Finanzbranche auf.
Die Finanzbranche wird in den nächsten Jahren einschneidenden Veränderungen (steigende Anzahl von FinTechs, Erhöhung der regulatorischen Anforderungen) unterworfen sein. Die Branche erhofft sich, durch den Einsatz von Big Data Wettbewerbsvorteile und Potenziale vor allem in den Bereichen Risikomanagement, Vertrieb und Marketing zu gewinnen. Es besteht kein Zweifel, dass durch Big-Data-Ansätze Geschäftsprozesse optimiert, Risiken besser kalkuliert und die Profitabilität gesteigert werden können: beispielsweise durch die Erstellung und Auswertung von Verkaufsgruppenanalysen, Kundenklassifizierungen und Verhaltensanalysen der Kunden (nahezu) in Echtzeit. Während die Bank of America bereits Transaktions- und Investitionsneigungsmodelle verwendet, um festzustellen, welche Kunden mit einer Kreditkarte oder Darlehenshypothek von einer Refinanzierung profitieren könnten, setzt die U.S. Bank im Marketing gezielt Big-Data-Tools ein, um Kunden personalisierte Produkte und Lösungen anbieten zu können. Auch das Risikomanagement profitiert maßgeblich von der raschen Erkennung und Identifikation externer Risiken. Die Fähigkeit, zeitnah mit Kunden zu interagieren und so die Kundenzufriedenheit maßgeblich steigern zu können, zeigen erste Erfahrungsberichte aus der BBVA.[4][5]
Der Themenkomplex Big Data umfasst damit bereits schon heute einige Facetten und wird sich in den kommenden Jahren immer weiter ausdehnen. Im Ziel steht dabei, die fachliche Anwendung mit technischen und methodischen Verfahren zu verknüpfen. Die technischen Möglichkeiten sind groß und die Implementierung intelligenter Methoden zur Strukturierung dieser Daten liefern dem Anwender neue Erkenntnisse, z. B. zur Effizienzsteigerung von Marketingmaßnahmen. Gerade durch diese Verknüpfung wird für den Anwender von Big-Data-Tools ein Mehrwert generiert.
Big-Data-Framework
Das vom zeb vorgeschlagene Big-Data-Framework baut darauf auf und setzt sich aus den Prozessschritten der Zieldefinition, Datenquellenauswahl, Datenvorverarbeitung und Data Mining bis hin zur Entwicklung der fachlichen Anwendung zusammen. Das Framework orientiert sich an einem klassischen Knowledge-Discovery-Prozess mit dem Ziel, unbekannte Zusammenhänge in großen Datenbeständen aufzudecken und zu identifizieren[6].
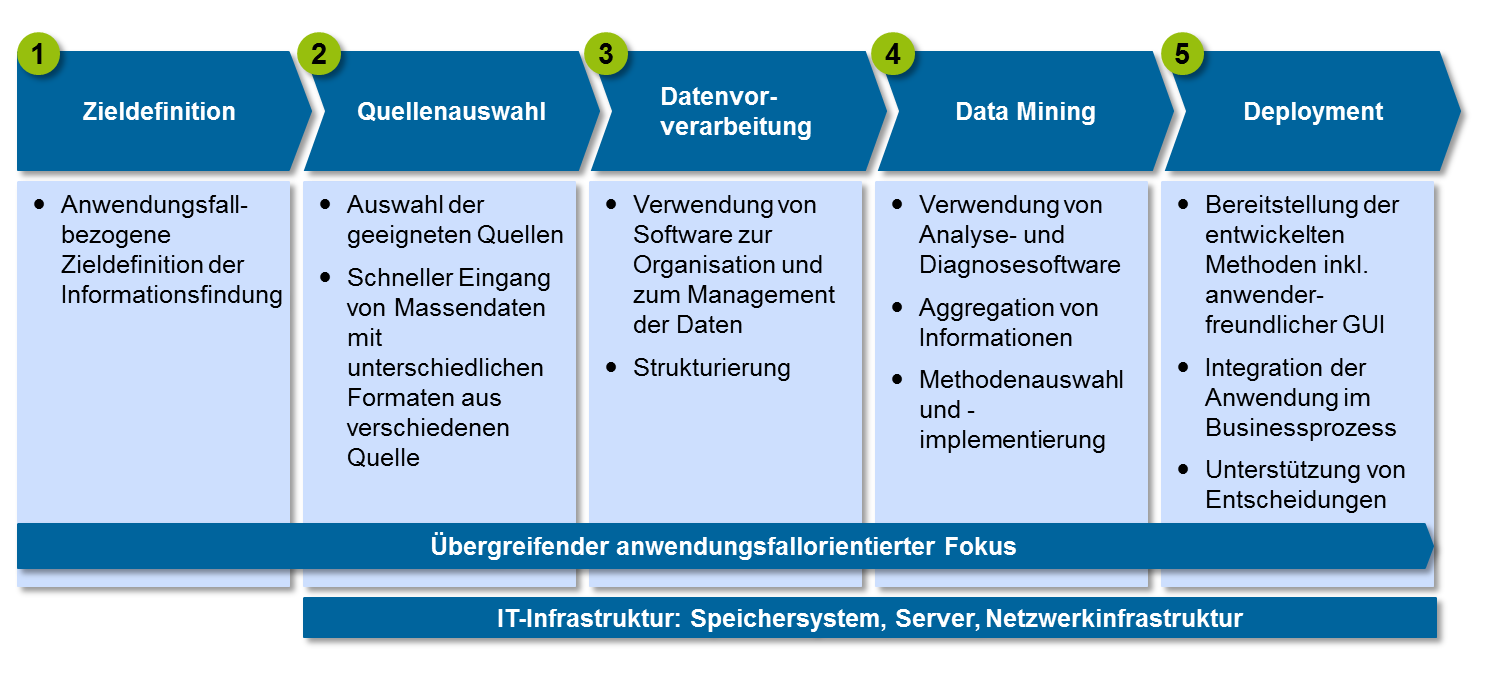 Abbildung 1: Big-Data-Framework
Abbildung 1: Big-Data-FrameworkDer erste und der letzte Prozessschritt sind auf die fachliche Anwendung ausgerichtet. Sie bilden für die stark technisch getriebenen Schritte zwei bis vier einen Rahmen. Nur durch die enge Verzahnung zwischen der technischen und fachlichen Welt kommt der Mehrwert zum Tragen.
Im ersten Prozessschritt wird mit einer streng fachlichen Perspektive das Ziel der Datenverarbeitung und der potenziellen Informationsgewinnung konkretisiert.
So konzentriert sich im Anschluss der zweite Prozessschritt auf die Auswahl der jeweiligen Datenquellen mit Blick auf den spezifischen Anwendungsfall. An dieser Stelle gilt es, in die Überlegung die potenziellen Daten und Merkmale einzubeziehen, aus denen man sich insbesondere auch aus fachlicher Sicht einen Informationsmehrwert erhofft. Als Datenquellen kommen hierbei interne Daten infrage, die bereits in vorhandenen Kernbankenlösungen zur Verfügung stehen. Ebenso beinhaltet dies die Anbindung geeigneter externer Datenquellen (z. B. Marktdaten und Auskunfteien) und die Verarbeitung von öffentlich verfügbaren Daten beispielsweise aus sozialen Netzwerken und von Internetsuchdiensten.
Der dritte Prozessschritt umfasst die Datenvorverarbeitung. Hierbei werden die relevanten Informationen unterschiedlicher Datenquellen in den institutseigenen Datenhaushalt überführt und strukturiert. Besonderes Augenmerk in diesem Prozessschritt fällt ebenso auf die Konsistenz- und Plausibilitätsprüfung der Daten, um den hohen Ansprüchen an die Datenqualität, Aktualität und Validität gerecht zu werden. Gerade die Sicherstellung von aktuellen und validen Daten ist eine große Herausforderung beim Aufbau und der Weiterverarbeitung des Datenhaushaltes.
Im vierten Prozessschritt, dem Data Mining, durchlaufen die Daten Analyseprozesse. Darin enthalten sind beispielsweise das Erkennen von Ausreißern, Klassifizierung der Daten, Mustererkennung und Anwendung von Prognose- oder Regressionsverfahren. Innerhalb der Daten werden Einflussfaktoren identifiziert, die sich zusammen zur Modellierung mehrdimensionaler oder teilweise auch nicht linearer Zusammenhänge eignen und sich als besonders relevant herausstellen. Zum Einsatz kommen dabei unter anderem statistische Verfahren und maschinelle, intelligente Algorithmen und Heuristiken. Solche Verfahren stellen zugleich eine schnelle Reaktionszeit auf sich ändernde Rahmenbedingungen sicher. Ziel dieser Methoden ist die Extraktion von Informationen und Erkenntnissen aus den Daten, welche dem Sinn und Zweck der fachlichen Anwendung dienen und eine bestimmte Aussage im Sinne einer Art Handlungsempfehlung unterstreichen.
Der fünfte und letzte Prozessschritt des Big-Data-Frameworks konzentriert sich auf die Entwicklung und Umsetzung der Anwendung inklusive einer grafischen Benutzeroberfläche. Darin eingeschlossen ist die Integration und Implementierung der Anwendung in die bestehende IT- und Prozesslandschaft. Hierbei kommen automatisierte Lösungen zum Einsatz, welche die Entscheidungsprozesse des Anwenders unterstützen.
Wertschöpfung in Banken
Die Anwendungsbereiche sind dabei vielfältig. Anhand des Beispiels der Wertschöpfungskette für Banken werden die Bereiche mit dem größten Potenzial (dunkelblau) hervorgehoben. Kerngebiete sind das Risikomanagement sowie das Produkt- und Kundenmanagement. Eng damit verknüpft sind sämtliche Marketing- und Vertriebsprozesse, bei denen eine gezielte Kundenansprache im Fokus steht. Ebenso im Fokus ist das Produktmanagement verbunden mit der Fragestellung nach der richtigen Produktplatzierung. Diverse Reportingfunktionen im Risikomanagement einerseits und im Vertriebscontrolling andererseits können durch Big-Data-Werkzeuge verbessert werden.
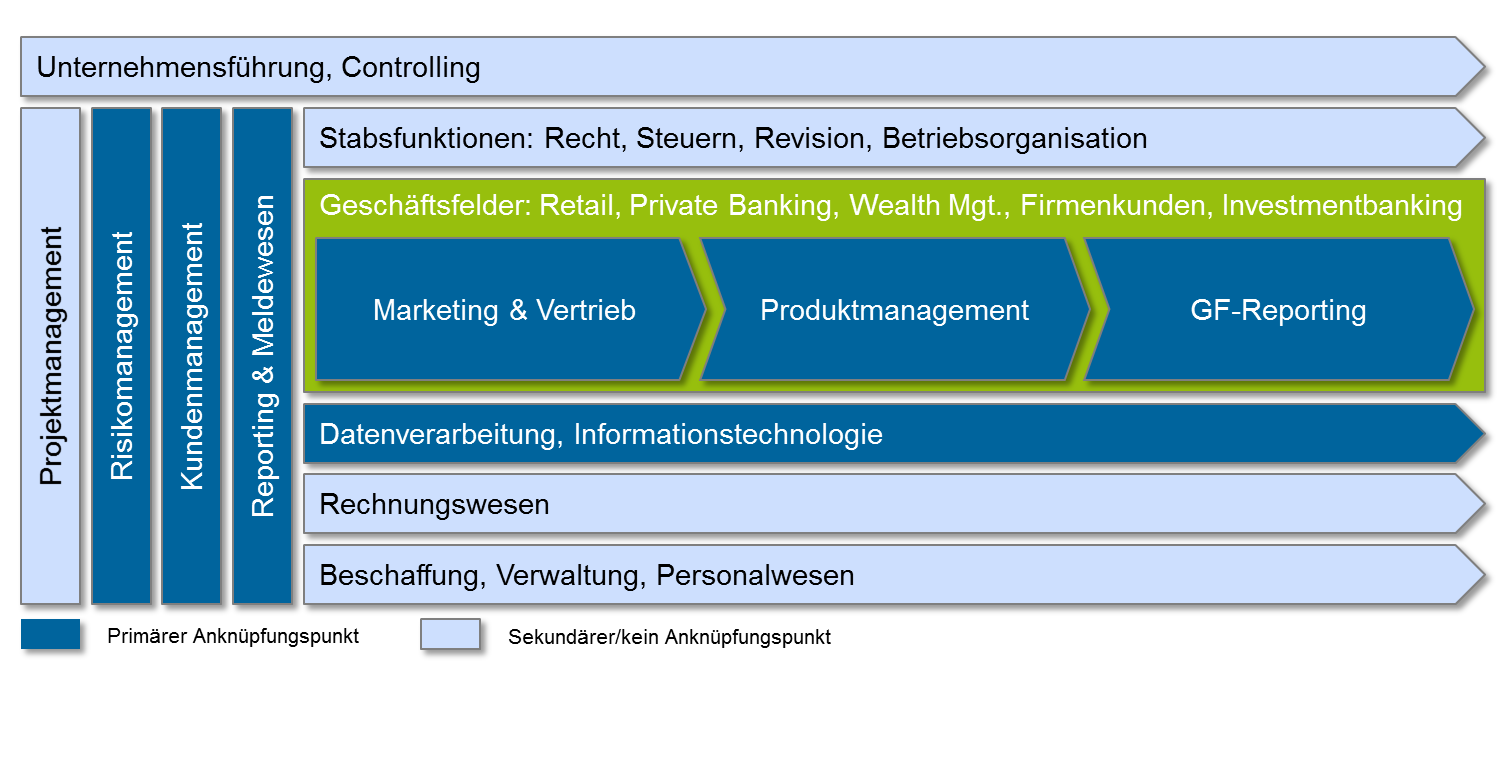 Abbildung 2: Wertschöpfung in Banken
Abbildung 2: Wertschöpfung in BankenAusgewählte Anwendungsbereiche im Risikomanagement erstrecken sich beispielsweise auf den Ausbau und die Optimierung der Risikofrüherkennung im Kreditwesen oder auf Auffälligkeitsprüfungen von Bestands- und Neukunden. Eng zusammenhängend stehen damit ebenso das Scoring von Kunden oder die Betrugsprävention. Der Mehrwert für den Anwender liegt in der Identifikation und dem Aufzeigen von potenziellen Risiken. So können rechtzeitig Handlungsmaßnahmen zur Verlustbegrenzung bzw. -vermeidung eingeleitet werden.
Darüber hinaus eignet sich das Big-Data-Framework dazu, im Kundenmanagement potenzielle Zielkunden bestimmter Produkte besser einzugrenzen und die Kundenbindung aktiv zu fördern. Ein zielgenaues Marketing, ein individuelles Pricing sowie eine spezifische Gestaltung des Produktportfolios stellen mögliche Anwendungsfelder dar. Für den Anwender wird z. B. durch die Erstellung eines individuellen, spezifizierten Kundenprofils eine bessere Beratung ermöglicht. Ebenso können abwanderungsgefährdete Kunden identifiziert werden. Die Erhöhung der Abschlusswahrscheinlichkeit bestimmter Finanzprodukte stellt neben einem effizienten Ressourceneinsatz ein weiteres Asset für den Anwender dar. So profitieren nicht nur Banken, sondern ebenso Versicherungsgesellschaften vom Einsatzspektrum des Big-Data-Frameworks.
zeb empfiehlt, im Rahmen einer Vorstudie das Potenzial möglicher Big-Data-Projekte unter Kosten-Nutzen-Aspekten zu evaluieren. Zweck der Evaluierung ist die Definition eines konkreten Zielbildes eines Big-Data-Projekts und die Identifikation von kundenspezifischen Anwendungsbereichen. Darin enthalten sind ebenso die Analyse, Bewertung und Auswahl von internen und externen Datenquellen, die Prüfung der Umsetzbarkeit unter wirtschaftlichen Gesichtspunkten sowie das Aufzeigen von Chancen und Risiken. Ergebnis der Vorstudie ist ein Projektplan zur Umsetzung und eine konkrete Identifikation der Big-Data-Potenziale.
Wichtiger Aspekt beim Umgang mit Daten ist die Wahrung der Datenschutzgesetze. Hier werden einige Leitplanken insbesondere bei der Verarbeitung von sensiblen personenbezogenen Daten vorgegeben. Die Einhaltung des Datenschutzes stellt jedoch für die Anwendung und Implementierung der aufgezeigten Lösungen kein Hindernis dar, obgleich dies bei der Entwicklung nicht aus den Augen gelassen werden darf.
Ein effizienter Ressourceneinsatz gepaart mit intelligenten Methoden aus dem Big-Data-Toolset hilft Banken und Versicherungen, je nach Anwendungsfall Risiken besser zu identifizieren und zu steuern sowie auf der Marketingseite kostenschonend und zielgenaue Maßnahmen zur Kundenbindung und -gewinnung zu initiieren. So werden einerseits Verluste reduziert, andererseits Umsätze gesteigert und Potenziale ausgeschöpft.

