Was ist Big Data?
Unter Big Data werden besonders große Datenmengen, der Umgang mit diesen sowie deren Einbindung in Entscheidungs- und Steuerungsprozesse verstanden. Neben intern vorrätigen und aufbereiteten Daten wie CRM/Kundendaten oder erstellten Marktanalysen, werden vermehrt auch externe Daten herangezogen, beispielsweise für die Risikomessung und -steuerung. Dabei werden auf externer Ebene Daten unterschieden, die frei verfügbar sind oder bereits aufbereitet der Bank zur Verfügung gestellt werden. Die Vielfalt so gesammelter Daten reicht von strukturierten Daten bis hin zu unformatierten Textzeilen, beispielsweise von einer Social Media Plattform.
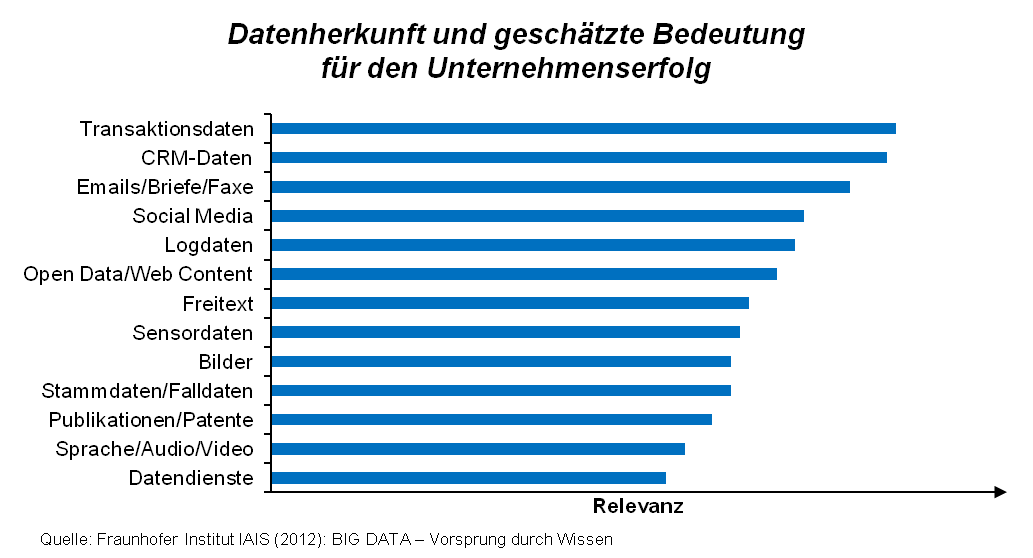 Abbildung 1:Datenherkunft und geschätzte Bedeutung für den Unternehmenserfolg
Abbildung 1:Datenherkunft und geschätzte Bedeutung für den UnternehmenserfolgWelche Potentiale liegen in Big Data für das Risikomanagement?
Durch Erhöhung der statistischen Trennschärfe kann der Einsatz von Big Data vor allem die Analyse- und Modellqualität im Risikomanagement steigern (z.B. von Antrags- & Verhaltensscorecards). Ergänzt durch die beschleunigte Informationsbereitstellung können so Steuerungsimpulse rascher erarbeitet und interpretiert werden. Ferner ermöglichen Szenariosimulationen unter Einbeziehung großer Datenmengen ein effektiveres Erkennen von Risikokonzentrationen und erlauben so schnellere Reaktionen auf neue Marktentwicklungen. Auch bezüglich Betrugserkennung kann Big Data zur Identifikation von Mustern angewandt werden, um durch den Abgleich von internen und externen Daten Betrugsfälle (beispielsweise Geldwäsche oder Kreditkartenmissbrauch) präziser, schneller und mit geringerem manuellem Aufwand zu identifizieren. Die neue Datenvielfalt machen sich bereits innovative Start-Ups (z.B. Kreditech) zu Nutze, die die umfassenden Möglichkeiten, sich im Risikomanagement in Nischen zu positionieren oder Joint-Ventures mit klassischen Finanzhäusern einzugehen, ergriffen haben.
Neben den Vorteilen für das Risikomangement sieht die Branche auch in anderen Anwendungsgebieten umfassende Potentiale durch Big Data. So können, wie es in anderen Branchen bereits zur Praxis geworden ist, beispielsweise durch das Sammeln von Web-Click-Strömen und Geo-Location-Daten passgenaue Produktangebote mit intelligenter Preissetzung erstellt werden. Neukunden sowie Bestandskunden sollen so besser an das Unternehmen gebunden werden. Auch die Anwendung von Big Data im algorithmenbasierten Trading, das schon heute einen substanziellen Anteil der täglichen Börsentransaktionen darstellt, soll nicht unerwähnt bleiben.
Gibt es bereits Erfahrungen auf diesem Gebiet?
Zahlreiche Banken haben bereits mit der Umsetzung von Big-Data Projekten begonnen. Als Umsetzung im Risikocontrolling ist das Beispiel der Bank UOB aus Singapur hervorzuheben, die ein Big Data basiertes Risikosystem erfolgreich testete, welches mit Hilfe von In-Memory-Technologie (Datenhaltung im Arbeitsspeicher) den Umgang mit Big Data praktikabel macht und die Kalkulationszeit des Gesamtbankrisikos (Value-at-Risk) von etwa 18 Stunden auf wenige Minuten reduziert. Dadurch wird es zukünftig möglich sein, Stresstests nahezu in Echtzeit auszuführen und auf neu eintretende Risiken rascher zu reagieren. Eine weitere Erfolgsgeschichte mit Big Data-Technologie im Rahmen existenter Geschäftsmodelle wurde von Morgan Stanley umgesetzt. Die Bank entwickelte ihre Fähigkeiten in der Big Data-Verarbeitung und optimierte damit ihre Portfolioanalyse hinsichtlich Umfang und Ergebnisqualität. Es wird erwartet, dass die so entwickelten Prozesse insbesondere durch automatisierte Mustererkennung und gesteigerte Nachvollziehbarkeit das Risikomanagement maßgeblich verbessern werden.
Als erfolgreicher Nischen-Player gilt die deutsche Firma Kreditech, die Kreditwürdigkeitsbewertungen von Privatpersonen anbietet. Dabei wird primär auf Standortdaten, Daten aus sozialen Netzwerken, Web-Analysen und Daten mit Bezug auf Online-Kaufverhalten abgestellt. Eingespeist in einen „Big Data-Pool“ werden so bis zu 10.000 Datenpunkten pro Bewertung berücksichtigt. In ähnlicher Weise geht das amerikanische Unternehmen Kabbage vor, das auf Grundlage von Big Data Kredite zur Vorfinanzierung und Bereitstellung von Working Capital an Firmenkunden vergibt. Die verwendeten externen Daten stammen dabei unter anderem von Verkaufsplattformen wie Amazon, Zustelldiensten und Social-Media-Plattformen. Ein Spezialist im Compliance Bereich ist die Firma Paymint, die auf Grundlage ihrer Big-Data-Software zur dynamischen Betrugsmustererkennung gegen Kreditkartenbetrug vorgeht. Dabei werden je nach Größe des Kreditkartenanbieters mehrere Milliarden Transaktionen monatlich analysiert.
Worauf muss zur erfolgreichen Umsetzung von Big Data geachtet werden?
Um der Komplexität und Breite des Themas Big Data strukturiert zu begegnen, empfiehlt zeb einen evolutionären Umsetzungspfad. Als erster Schritt sollte der Schwerpunkt auf der Erschließung interner Daten liegen. Anschließend wendet man sich wertstiftenden zusätzlichen Datenquellen zu, sofern der Grenznutzen der Einbindung die zusätzlichen Kosten übersteigt. Da mehr Daten jedoch nicht zwangsläufig auch zu gesteigerter Datenqualität und Auswertbarkeit führen, ist ein integrierter Prozess mit Test-, Lern- und Anpassungsschleifen essentiell. Auch kleine Schritte und Verbesserungen sind entscheidend, um bei der Umsetzung etwaigen Risiken und Stolpersteinen entgegen zu treten.
Gemäß einer Studie des Fraunhofer Instituts liegen die größten Barrieren für erfolgreiche Big Data-Umsetzungen im Datenschutz und in der Datensicherheit, gefolgt von budgetären Restriktionen, anderweitiger Prioritätensetzung, fehlender Expertise und mangelndem Bewusstsein der Thematik. Weniger im Vordergrund stehen technische Hindernisse wie unbrauchbare Daten oder unausgereifte Technologie. Dies verdeutlicht die grundsätzliche Realisierbarkeit der Potentiale von Big Data (im Risikomanagement), sofern identifizierten Hürden mit entsprechender Kompetenz entgegen gewirkt wird.
Fazit
Dass Big Data besonders in der Finanzbranche ein zukunftsträchtiges Thema sein wird, haben vor allem innovative Nischenanbieter bereits bewiesen. Die umfassenden Möglichkeiten, die sich aus der Anwendung im Risikomanagement für etablierte Banken ergeben, werden oftmals noch nicht ausgeschöpft. Um diese aufzuzeigen, rät zeb zu einer initialen Potentialanalyse, an deren Ende die Auswahl des Pilotprojekts mit dem besten Kosten/Nutzen Verhältnis steht. Mit überschaubarem (Daten-)Umfang sollen so Erfahrungen gesammelt werden und durch überzeugende Ergebnisse das bankinterne Buy-In für die Aufnahme von Big Data in Analyse- und Entscheidungsprozesse erzielt werden. zeb empfiehlt, sich frühzeitig mit Big Data zu befassen, um nachhaltig im dynamischen Wettbewerbsumfeld zu bestehen.


