Ausgangslage: europaweite Vergleichbarkeit von Kreditrisikoparametern angestrebt
In der GL werden allgemeine Anforderungen an Prozesse und Daten (z. B. bezüglich Konservativitätsaufschlägen, der Berücksichtigung von Experteneinschätzungen, des Vorgehens bei Validierungen und Weiterentwicklungen) sowie spezifische Anforderungen an die Methodik zur Schätzung von Risikoparametern gestellt. Diese betreffen einerseits die PD-Schätzung u. a. in Bezug auf Schätzmethoden, Risikotreiber und die Berechnung von Ausfallraten und andererseits die CCF- und LGD-Schätzung u. a. in Bezug auf Berechnungen des (Durchschnitts-)LGD sowie die Berücksichtigung von Kreditsicherheiten. Eine besondere Neuerung ist dabei die Konkretisierung des Umgangs mit zum Stichtag der Schätzung im Ausfall befindlichen Forderungen. Diese sind in Zukunft vollständig in die LGD-Parameterschätzung einzubeziehen. Ferner präzisiert der RTS das Vorgehen zur Ermittlung des Downturn Adjustment für LGD und CCF – eine wesentliche Konkretisierung ist dabei die Anzahl notwendiger Analysen bezüglich der Abhängigkeit von ökonomischen Faktoren. Abbildung 1 gibt einen Überblick über die genannten Inhalte.
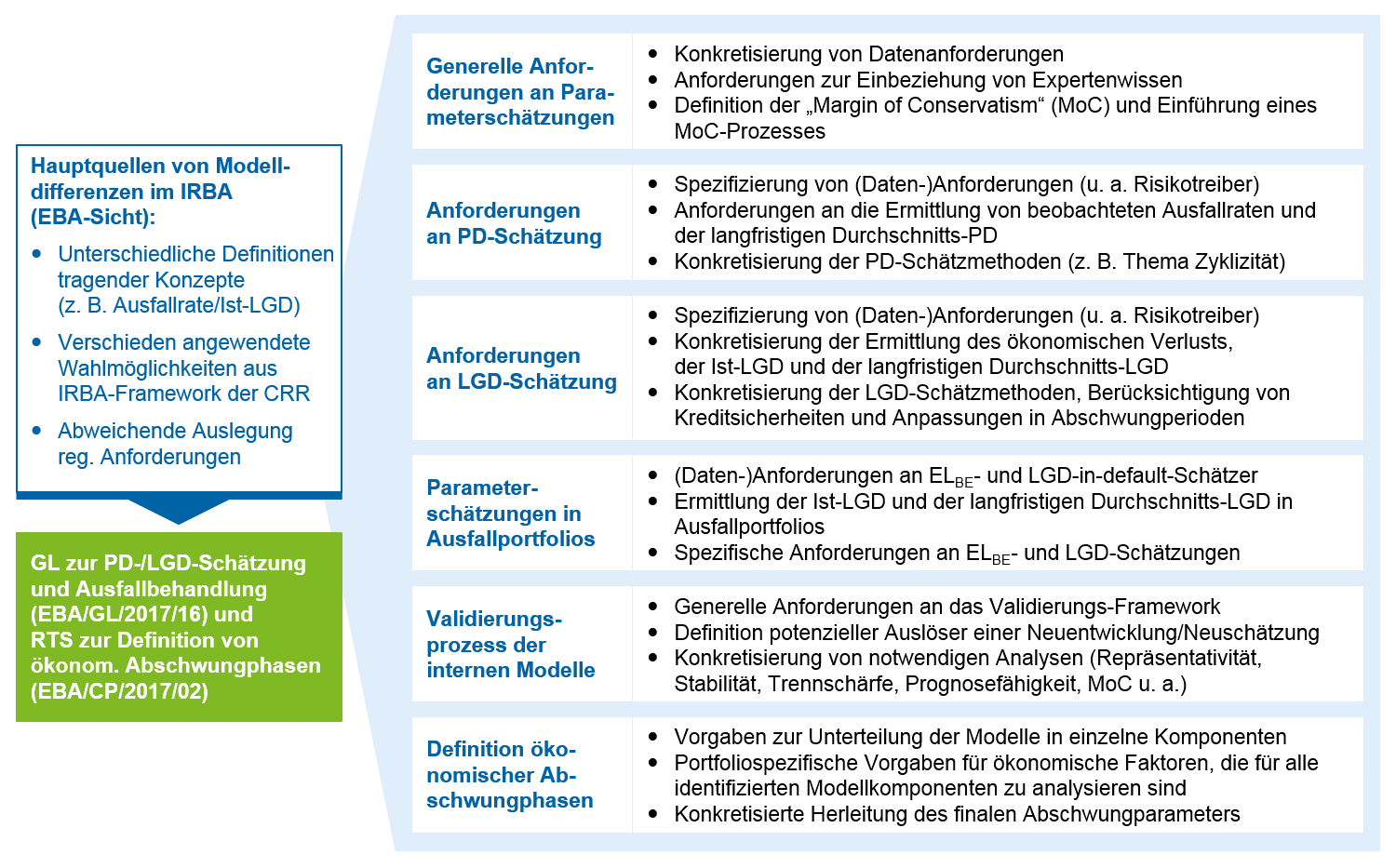 Abbildung 1: Überblick über die Inhalte der Phase 3 des Future of the IRBA
Abbildung 1: Überblick über die Inhalte der Phase 3 des Future of the IRBAIn diesem Artikel greifen wir die drei methodischen Konkretisierungen aus GL und RTS heraus, die seit dem frühen Konsultationsstadium für wesentlichen Diskussionsbedarf hinsichtlich Komplexität/Umsetzungsaufwand sowie der Auswirkungen auf die Eigenmittelanforderungen in der DACH-Region gesorgt haben:
- den Konservativitätsaufschlag („Margin of Conservatism“, MoC)
- die Berücksichtigung von ausgefallenen Forderungen im Rahmen der LGD-Schätzung
- die Herleitung von ökonomischen Abschwungphasen zur Berechnung des Downturn-Aufschlags auf LGD und CCF
Transparenter Prozess zur konservativen Korrektur von Schätzfehlern eingefordert
Der MoC ist ein bestehendes Konzept zur Berücksichtigung von Unsicherheiten und Fehlern bei der Parameterschätzung. Diese sollen minimiert bzw. korrigiert werden, wobei im Zweifel konservative Auswirkungen auf die Eigenmittelanforderungen in Kauf genommen werden sollen. Die bestehenden Vorschriften in der CRR[6] und im RTS zur Prüfmethodik („Assessment Methodology“)[7] sind wenig konkret und besagen lediglich, dass es einen MoC bei erwarteten Schätzfehlern bezüglich Methoden und Daten, bei Korrelation zwischen Ausfall- und Ziehungsraten, bei Änderungen von Kreditvergaberichtlinien sowie bei Inkonsistenz in Definitionen und Richtlinien geben soll. Die Höhe der MoC soll dabei z. B. von der Dauer des Datendefizits abhängen und einen Anreiz setzen, die jeweiligen Defizite zu korrigieren und Unsicherheiten durch z. B. Modellanpassungen zu minimieren. Diese Anforderungen werden von deutschen Instituten bislang häufig pragmatisch gelebt. So ist zu beobachten, dass MoC etwa durch Aufschlag einer Standardabweichung auf den Schätzparameter oder komplett durch Expertenschätzungen quantifiziert werden.
Zukünftig sollen solche „Daumenregeln“ auf höchstem Aggregationslevel vermieden werden und einem geordneten MoC-Prozess weichen. Von Unsicherheit betroffene Risikoparameter sind durch „geeignete“ Anpassungen von Schätzmethoden und -daten zu korrigieren. Für verbleibende Unsicherheit ist ein MoC auf Ebene des betroffenen Risikoparameters zu quantifizieren.
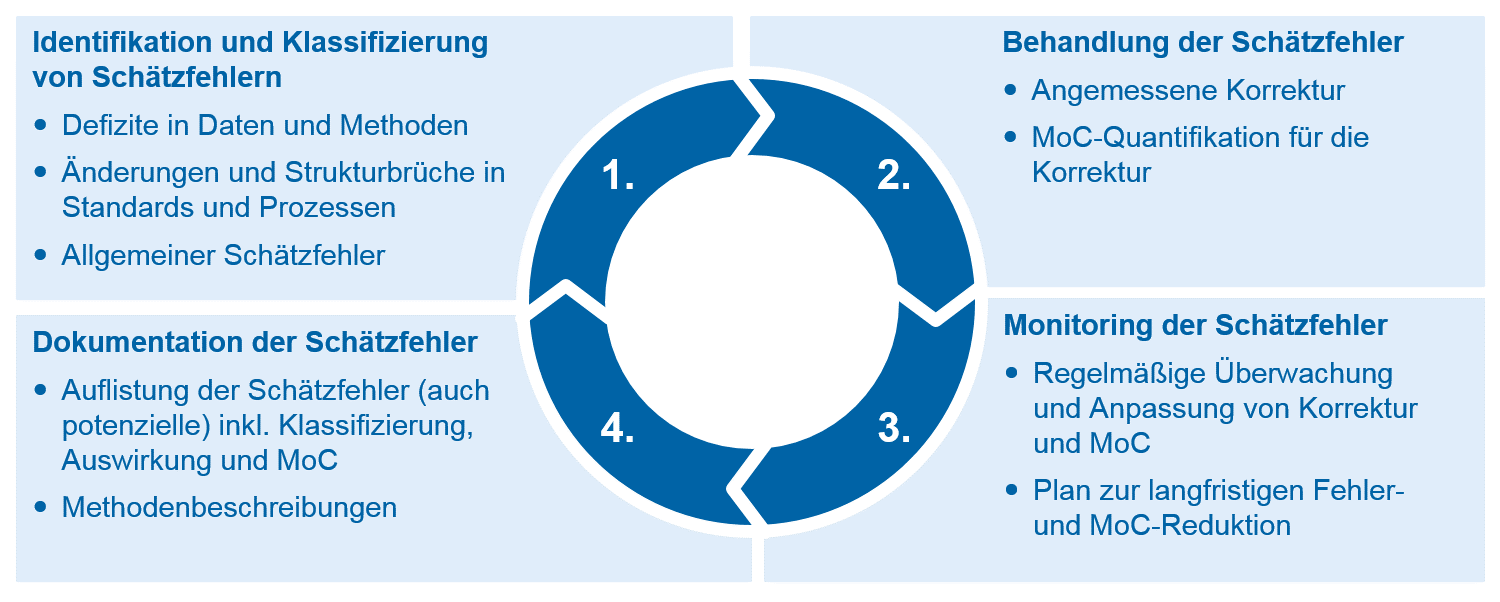 Abbildung 2: Der MoC-Prozess
Abbildung 2: Der MoC-Prozess- Der MoC-Prozess startet mit der Klassifizierung der Fehler in Datendefizite, Repräsentativitätsdefizite, generelle Schätzfehler (insbesondere aus Modelldefiziten) und sonstige Unsicherheiten.
- Im zweiten Schritt erfolgt die eigentlich „angemessene“ quantitative Korrektur, bei der z. B. fehlende Werte durch verwandte Daten ersetzt werden, um danach den Einfluss dieser Korrektur auf die betroffenen Parameter zu messen und somit einen MoC abzuleiten. Was sich in der Theorie recht einfach und smart anhört, wird in der daten- und modellgetriebenen Praxis jedoch tatsächlich entweder nur rudimentär möglich sein oder eine hohe Komplexität nach sich ziehen.
- Anschließend sind die Korrekturen und die MoC zudem in wiederkehrenden Zeiträumen zu überwachen und ggf. anzupassen. Dazu gehört die Erstellung und Verfolgung eines Plans zur langfristigen Reduktion des Schätzfehlers und damit einhergehend des MoC.
- Im vierten Schritt sind die MoC in den entsprechenden Modell- und Methodikdokumentationen zu beschreiben. Dazu gehört eine komplette Liste mit allen potenziellen und tatsächlichen Fehlern inklusive deren Auswirkung auf den entsprechenden Parameter oder die Modellkomponenten, eine Methodenbeschreibung für die Korrektur zur Quantifizierung der MoC sowie der in Schritt 1 ermittelten Klassifizierung des Fehlers.
Auf diese Weise wird transparent, welche Methoden innerhalb der Klassen angewandt wurden und ob Konsistenz bei der Behandlung gleichartiger Fehler herrscht. Der vorgeschlagene MoC-Prozess erfordert von europäischen Banken somit eine detailliertere und damit auch genauere Behandlung von Fehlern und Unsicherheiten in Daten und Modellen. Dies führt nicht zwangsläufig zu höheren Kapitalanforderungen, wohl aber zu höheren Aufwänden bei der Identifizierung, Quantifizierung, dem Monitoring und der Dokumentation.
Variabilität von Kapitalanforderungen durch sich im Ausfall befindende Forderungen – Sonderbehandlung genauer definiert
Als einen Haupttreiber für die Variabilität von Kapitalanforderungen und damit für mangelnde Vergleichbarkeit von IRB-Modellen hat die EBA die Behandlung von ausgefallenen Forderungen identifiziert. Daher setzt sie nun neue Standards für die Schätzung von LGD in-default und Expected Loss Best Estimate (ELBE).
In die Datengrundlage zur LGD-Schätzung sind diesbezüglich zukünftig explizit auch zum Datenstichtag noch nicht abgeschlossene Ausfälle einzubeziehen.[8] Die EBA unterscheidet dabei zwei Fälle. Hat die Länge des Ausfalls eine durch das Institut definierte produktspezifische maximale Verwertungsdauer überschritten, so wird der Ausfall als abgeschlossen angesehen. Es wird dann davon ausgegangen, dass keine Erlöse mehr zu erzielen sind. Für die übrigen nicht abgeschlossenen Ausfälle sind die erwarteten zukünftigen Rückflüsse und Kosten der jeweiligen Forderungen zu schätzen (ggf. auch über die maximale Verwertungsdauer hinaus). Dabei sollen sich Institute an ähnlichen Fällen in der Vergangenheit orientieren, und zur Reduktion der Unsicherheit durch die geschätzten Zahlungsströme ist der resultierende LGD darauf aufbauend mit einer MoC zu versehen. Das Vorgehen zur Einbeziehung und Schätzung von erwarteten Cashflows ist für die Institute eine große methodische Neuerung und Herausforderung. Hintergrund für dieses komplizierte Verfahren ist, dass es sich bei nicht abgeschlossenen Ausfällen überproportional oft um langwierige Alt-Fälle handelt, die sich strukturell von anderen Ausfällen unterscheiden und deren Nichtberücksichtigung zu optimistischen Verzerrungen führen würde.
Die geschätzten Rückflüsse auf nicht abgeschlossene Ausfälle sind anschließend in die Schätzung des LGD in-default und des ELBE einzubeziehen. Neu ist dabei die Konkretisierung, dass sich diese Parameter nicht ausschließlich auf den EAD bei Ausfall, sondern auch auf den jeweils verbleibenden Forderungsbetrag zu festgelegten Referenzpunkten beziehen sollen. Die Referenzpunkte können ereignisorientiert definiert sein (z. B. „Verwertung der (größten) Sicherheit ist erfolgt“), zeitlich (z. B. „Forderung befindet sich X Monate/Jahre im Ausfall“) oder beides (z. B. „X Monate/Jahre nach Verwertung der Sicherheit“). Modelle für den LGD in-default sind somit abschnittsweise überlappend zu schätzen – jeweils von einem Referenzpunkt bis zum Ende des Verwertungsprozesses bzw. bis zur Wiedergesundung. Zum Datenstichtag im Ausfall befindliche Forderungen werden bei der Schätzung nur in den Abschnitten des Modells berücksichtigt, zu denen auch tatsächliche Rückflüsse vorliegen, d. h., es laufen keine rein fiktiven Datenpunkte in eine Schätzung.
Im Unterschied zum ELBE soll der LGD in-default unerwartete Risiken berücksichtigen (durch Downturn Adjustment, MoC und weitere Aufschläge für z. B. idiosynkratische Unsicherheiten). Der ELBE stellt den erwarteten Verlust bei aktueller ökonomischer Lage und ohne MoC dar. Die Differenz aus LGD in-default und ELBE ist als Eigenmittel für den unerwarteten Verlust in Säule I vorzuhalten.
Institute stehen nun zunächst vor der Aufgabe, die zukünftigen Rückflüsse der sich zum Datenstichtag im Ausfall befindenden Forderungen zu schätzen – die vermutlich größten Hebel sind dabei die zu definierenden Ereignis- und Referenzpunkte.
Bei der Wahl der Referenzpunkte und der Definition der maximalen Verwertungsdauer sind die Implikationen für die Schätzung zu berücksichtigen. Eine konservative Festlegung dieser Stellhebel kann a priori zu höheren LGD-Schätzungen führen, vermeidet aber ggf., dass Modelabschnitte anhand kleiner Stichproben geschätzt werden müssen, was wiederum einen höheren MoC nach sich ziehen muss. Dieser Trade-off ist bei der Modellierung ebenfalls zu beachten.
Datenintensive Analysen für die Berücksichtigung von ökonomischen Abschwungphasen in LGD und CCF notwendig
LGD- und CCF-Schätzungen sollen die Bedingungen ökonomischer Abschwungphasen (Economic Downturn) widerspiegeln. Institute haben diese Anforderung bisher unterschiedlich definiert und methodisch unterlegt. Die EBA hat diese Schwäche erkannt und den Begriff der Abschwung- und Downturn-Phase nun über die Dimensionen Art, Schwere und Dauer definiert. Zudem schlägt sie einen konkreten Prozess- und Methodenstandard zur Quantifizierung eines Downturn-Aufschlags auf die CCF- und LGD-Schätzer vor. Abbildung 3 gibt einen Überblick über die Konkretisierungen der entsprechenden RTS.
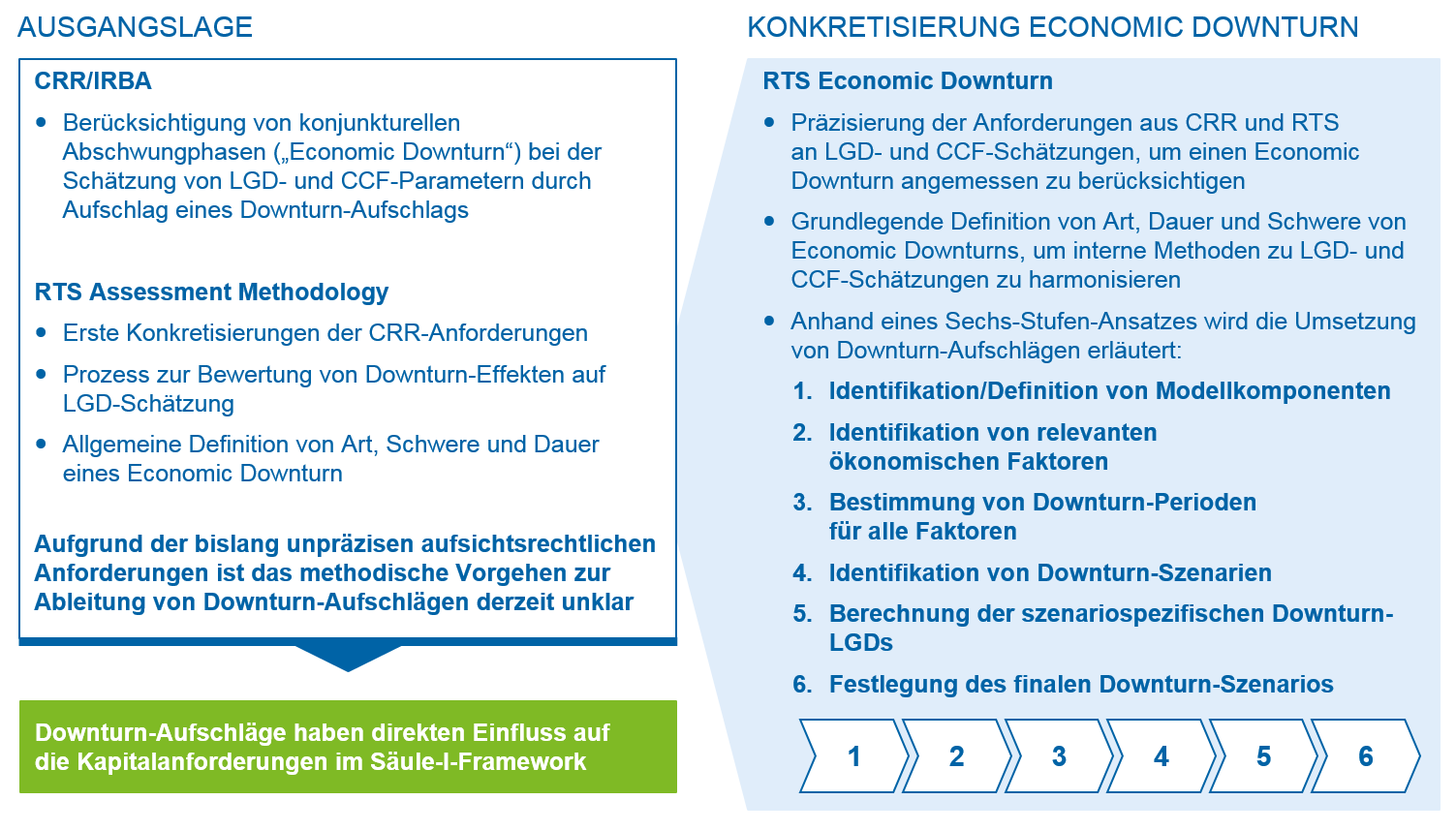 Abbildung 3: Schematische Darstellung des Prozesses zur Ableitung des Downturn-Aufschlags
Abbildung 3: Schematische Darstellung des Prozesses zur Ableitung des Downturn-Aufschlags- Zunächst sollen Institute die für die Schätzung relevanten Modellkomponenten ihrer LGD- und CCF-Modelle bestimmen – insbesondere wird in dem Zusammenhang von einer Berücksichtigung der häufig bimodalen Verteilungseigenschaften gesprochen. Diesen wird typischerweise über getrennte LGD-Submodule für Abwicklungen, Wiedergesundungen und Wiedergesundungswahrscheinlichkeiten in der Modellarchitektur Rechnung getragen.
- Für jede dieser Modellkomponenten sollen in einem zweiten Schritt ökonomische Faktoren ermittelt werden, die mit den historischen Realisationen der Modellkomponenten korrelieren. Die mindestens zu untersuchenden Faktoren sind von der EBA in portfoliospezifischen Listen segmentspezifisch vorgegeben und umfassen u. a. BIP-Wachstum, Arbeitslosenquote, Zinssätze, Segmentierung nach Branchen, Ausfallquoten und Kreditverluste.
- In Schritt 3 soll für jeden Faktor die sog. Abschwungperiode als das Jahr mit der schlechtesten Realisierung in den letzten zwei Konjunkturzyklen (mindestens 20 Jahre) bestimmt werden.
- Anschließend sollen im vierten Schritt die identifizierten Abschwungperioden einer ökonomischen Argumentation folgend zu Downturn-Szenarien geclustert werden (intuitives Beispiel ist die „Finanzkrise“ als Jahr 2007 und folgend).
- In Schritt 5 wird für jedes Downturn-Szenario eine Downturn-Realisation je Modellkomponente ermittelt. Es erfolgt jeweils der Ansatz der (durchschnittlichen) Realisationen aus der zugehörigen Abschwungperiode oder, falls eine Modellkomponente nicht durch das Downturn-Szenario betroffen ist, des langfristigen Durchschnitts der Realisationen der Modellkomponente.[9]
- Aus den in Schritt 5 ermittelten Werten für die Modellkomponenten lässt sich dann der (aggregierte) LGD oder CCF für das jeweilige Downturn-Szenario berechnen. Maßgeblich für die Quantifizierung des Downturn-Aufschlags ist das Downturn-Szenario, das den konservativsten LGD bzw. CCF hervorbringt.
Der RTS sagt nicht aus, wie der Downturn-Aufschlag konkret auf Basis des identifizierten Downturn-Szenarios zu quantifizieren ist. Plausibel erscheint die Ableitung eines Aufschlag-Faktors als Quotient des Risikoparameters im Downturn-Szenario und seinem langfristigen Durchschnitt.
Die geschilderte Methodik wird für viele Institute einen erhöhten Aufwand für die Ermittlung (und Validierung) von Downturn-Aufschlägen darstellen. Je nach Modellarchitektur stellt bereits die Interpretation des Begriffs „Modellkomponente“ eine Herausforderung dar – beispielsweise wenn die Modellarchitektur nicht auf Trennung von Wiedergesundungen und Abwicklungen abstellt, sondern zwischen Blanko- und besicherten Anteilen (über SEQ-Modelle o. Ä.) trennt.[10] Des Weiteren stehen Institute vor der komplexen Aufgabe, alle ökonomischen Faktoren zu finden, die eine hinreichend ökonomisch begründbare Korrelation zu den Modellkomponenten aufweisen. Die dafür notwendige Datenhistorie dürfte in Instituten in der geforderten Länge selten vorhanden sein. Eine zusätzliche Herausforderung stellt die Festlegung von Abschwungszenarien dar. An dieser Stelle lässt die EBA Interpretationsspielraum bzw. größere methodische Freiheit. Es empfiehlt sich hier eine sorgfältige Analyse der Alternativen.
Ausblick zur Zukunft des IRB-Ansatzes
Die dritte Phase der EBA-Initiative zur Zukunft des IRB-Ansatzes sorgt methodisch für eine Angleichung der Schätzmodelle für IRB-Parameter, lässt den Instituten jedoch weiterhin Freiheitsgrade, um die Modelle spezifisch für das eigene Geschäft auszugestalten. Die Komplexität verschärft sich insbesondere für LGD-Modelle. Die neuen Anforderungen werfen schon heute ihre Schatten voraus und erfordern entsprechende Vorarbeit.
Bis 2021 sollen die Institute ihre Schätzverfahren konform zu den Neuerungen durch den Future of the IRBA ausgerichtet haben. Dazu werden umfangreiche Nachbearbeitungen von Datenhistorien notwendig sein, um eine geeignete Grundlage für angemessene Weiterentwicklungen zu schaffen, sei es bezüglich der hier vorgestellten Regelungen zum LGD oder zu den aus der Phase 2 des Future of the IRBA stammenden Anpassungen an der Ausfalldefinition. Dort wo keine fristgerechte, vollständige Konformität realistisch erscheint, sollten die MoC-Anforderungen antizipiert werden, um möglichst frühzeitig mit der Sammlung von Daten zu beginnen, die eine überzeugende Quantifizierung zukünftiger MoC ermöglichen.




