Neue Anforderungen in Richtung Realtime-Auswertung und Analyse des operativen Datenhaushalts
Beispielhaft seien hier die steigenden regulatorischen Initiativen und Anforderungen genannt, deren Erfüllung immer zeitnähere und detailliertere Informationen erfordert oder Anforderungen aus der Digitalisierungs-Strategie vieler Häuser, die häufig die Verfügbarkeit von Realtimen-Abwicklungsinformationen in den Vertriebsanwendungen voraussetzt.
Ein direkter Zugriff auf die Abwicklungssysteme kommt in der Regel aus Gründen der Stabilität und Performance der Abwicklungsprozesse nicht in Frage. So sollten bspw. Umsatzbuchungen im Tagesgeschäft nicht durch Auswertungen für das Kundenportal beeinflussen werden. Aber auch technische Hürden, wenn bspw. die operativen Systeme auf dem Host liegen und dezentrale Anwendungen versorgt werden sollen, oder Kostenimplikationen bei transaktionsorientierten Abrechnungsmodellen im Abwicklungsbereich, sprechen gegen einen direkten Zugriff auf die operativen Systeme.

Klassisches DWH: Extrahieren, Transformieren, Laden
Der Aufbau eines Datawarehouses (DWH), in welchem die benötigten operativen Daten gespeichert, aufbereitet und analysiert werden, war bisher ein bewährtes Lösungsmuster zur Erfüllung abwicklungsorientierter Informationsbedarfe.
 Abbildung1: Prinzipskizze der klassische DWH-Architektur
Abbildung1: Prinzipskizze der klassische DWH-ArchitekturDie benötigten operativen Daten werden aus den Quellsystemen selektiv extrahiert und in der Eingangsebene des DWHs (Staging Area) temporär zwischen gespeichert. Die Extraktion erfolgt in der Regel turnusmäßig (täglich, monatlich,…) und zu festen Zeitpunkten (z.B. nach der Tagesendverarbeitung). Innerhalb des DWHs werden die Daten schrittweise aufbereitet, normiert und in die Zieldatenstruktur transformiert. Das Zieldatenmodell wird schließlich persistiert, während die Ausgangsdaten in der Regel mit der nächsten Beladung überschrieben werden. Auswertungen und Analysen greifen ausschließlich auf das Zieldatenmodell zu, welches eine konsolidierte Sicht auf den jeweiligen Datenhaushalt beinhaltet. Technische Basis für ein klassisches Datawarehouse ist ein relationales Datenbankmanagementsystem mit einem standardisierten SQL-Zugriff für Abfragen.
Mit zunehmendem Umfang der Anforderungen stößt dieses Konzept allerdings an seine Grenzen:
- Hoher Umsetzungsaufwand: Kern des DWH-Konzepts ist die Transformation und Normierung der Ausgangsdaten in ein einheitliches Datenmodell. Diese Vorgehen führt zu vergleichsweise hohen Umsetzungsaufwänden, da das Zieldatenmodell zunächst übergreifend erarbeitet und abgestimmt werden muss und anschließend jede Transformation konzeptionell zu beschreiben, umzusetzen und zu testen ist, bevor konkrete Auswertungen erfolgen können.
- Eingeschränkte Flexibilität: Im klassischen Datawarehouse steht für Auswertung nur das vorab definierte Zieldatenmodell zur Verfügung. Eine flexible Einbindung zusätzlicher Datenquellen z.B. für Ad-hoc-Auswertungen ist in der Regel nicht vorgesehen und muss außerhalb der DWH-Welt erfolgen.
- Keine Rohdaten: Ziel eines Datewarehouses ist die Normierung und möglichst gleichartige Abbildung ähnlicher Sachverhalte, um spätere Auswertungen und Analysen zu vereinfachen. Dies ist für Fragen der Banksteuerung und Regulatory häufig sinnvoll (z.B. einheitliche Abbildung aller Kredite), steht aber im Wiederspruch zu operativeren Anforderungen, in denen Detailinformationen zu einzelnen Produkten benötigt werden (z.B. konkrete Konditionen für ein Baufinanzierung).
- Datenvolumen: Datawarehouses können zwar prinzipiell mit sehr großen Datenmengen umgehen, benötigen hierfür aber ab einem gewissen Umfang spezielle Datenbank- und Speicher-Hardware. Bei sehr großen Datenmengen steigen daher die Kosten typischerweise exponentiell an.
Data lake: Erst laden, dann transformieren
Das Data Lake-Konzept verspricht hier Abhilfe, indem zunächst alle für Analysezwecke benötigten Daten an einem Ort zentral und unverändert verfügbar gemacht werden. Erst im nächsten Schritt erfolgt im Rahmen von konkreten Auswertungen eine selektive Datenaufbereitung. Hierbei soll über den Einsatz von Big Data-Technologien eine performante, flexible und kostengünstige Verarbeitung sichergestellt werden können.
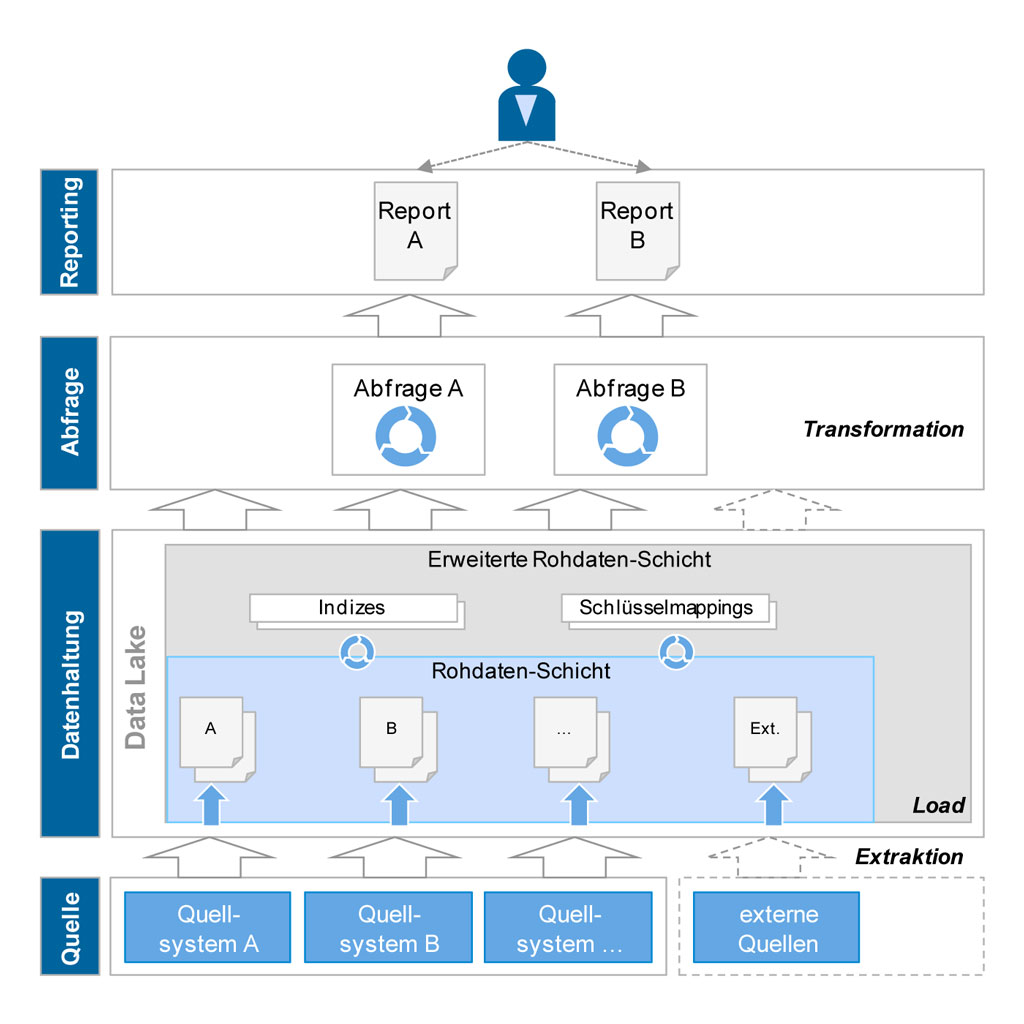 Abbildung2: Prinzipskizze der Data-Lake-Architektur
Abbildung2: Prinzipskizze der Data-Lake-ArchitekturDie Ausgangsdaten aus den Quellsystemen werden nach dem Data Lake-Konzept ohne logische Transformation direkt in eine Roh-Datenschicht geladen. Technologisch basiert diese aufgrund der genannten Einschränkungen in der Regel nicht auf einer relationalen Datenbank, sondern auf Filesystem-Strukturen (Hadoop) oder Key-Value-Strukturen. Beide Ansätze haben den Vorteil, mit Strukturänderungen auf Seiten des Quellsystems dynamisch umgehen zu können und heterogene Datenformate (auch unstrukturiert) verarbeiten zu können. Die Roh-Daten werden ggf. um Schlüsselmappings oder Indizes in einer erweiterten Roh-Datenschicht ergänzt, um performante Zugriffe zu ermöglichen, bleiben in ihrer Struktur jedoch unverändert. Abfragen und Auswertungen erfolgen direkt auf der Roh-Datenschicht, sind im Vergleich zum klassischen DWH aber deutlich komplexer, da die Vereinheitlichung und Konsolidierung von Informationen (Transformation) hier im Zuge der Abfragen erfolgen muss. Für die Definition und Verarbeitung dieser Abfragen stehen unterschiedliche Big Data-Technologien zur Verfügung, die über Verteilungsmechanismen auf Basis von Standard-Hardware eine hohe und kostengünstige Skalierbarkeit sicherstellen. Da die Transformation der Daten erst zur Laufzeit der Abfragen erfolgt, ist auch eine flexible Integration weitere Daten (z.B. externer Informationen) vergleichsweise einfach möglich. In der Regel werden externe Daten aber nicht im Data Lake persistiert, sondern lediglich über einen Verweis in den Metadaten bekannt gemacht.
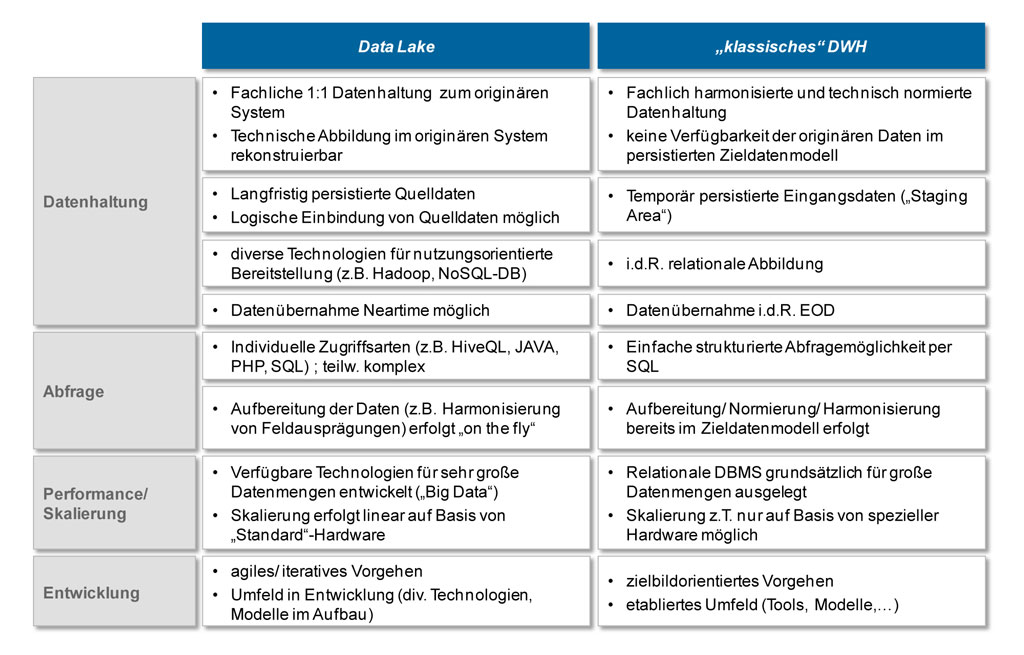 Abbildung 3: Gegenüberstellung Data-Lake – klassisches DWH
Abbildung 3: Gegenüberstellung Data-Lake – klassisches DWHVoraussetzungen für data lake Ansatz nicht unterschätzen
Der Data Lake-Ansatz ist eine vielversprechende Alternative neben dem klassischen Datawarehouse-Konzept, setzt aber auch die Erfüllung einer Reihe von Rahmenbedingungen voraus.
Zentrale Bedeutung kommt hier den Metadaten und deren Management zu, denn sie sind zwingende Voraussetzung für den dynamischen und sachgerechten Zugriff auf die Rohdaten. Die Metadaten müssen neben einer fachlichen und technischen Beschreibung der Inhalte des Data Lake, auch Informationen zur Zusammenführbarkeit und Transformierbarkeit der Roh-Daten beinhalten. Denn ob und wie die Kundendaten aus System A mit den Produktdaten aus System B zu verknüpfen sind, müssen die Ersteller von Abfragen und/oder das verwendete BI-Tool aus den Metadaten ermitteln können. Eine konsolidierte Schlüsselbeziehung wie im klassischen DWH, die eine einheitliche Verknüpfung für alle Auswertungen sicherstellt, gibt es im Data Lake nicht.
Insgesamt steigen dadurch auch die Anforderungen an die Nutzer eines Data Lake. Freie Analysen der Daten sollten nur von Experten (Data Scientist) durchgeführt werden, die die Zusammenhänge der Roh-Daten gut kennen. Vordefinierte Abfragen und Bericht oder auch Teildatenbestände mit einer umfassenden Metadatenbeschreibung hingegen können von einer breiten Nutzerschicht verwendet werden. Häufig werden beim Data Lake daher auch ein explorativer Experten-Bereich und ein abgesicherter Nutzer-Bereich unterschieden. Insgesamt bleibt festzuhalten, dass sich Komplexität und Aufwände von der Datenhaltungsseite zur Report- und Analyseerstellung verlagern.
Mehr Artikel auf BankingHub
Wesentliche Hausforderung stellt auch das Thema Security dar. Der Nutzen des Data Lake steigt mit der Breite und Tiefe der verfügbaren Daten. Gleichzeitig dürfen schon aus Compliance-Sicht nicht alle Nutzer Zugriff auf den gesamten Datenhaushalts eines Instituts haben. Dies erfordert entsprechende Security-Mechanismen, die den Zugriff so weit wie nötigt, aber so wenig wie möglich einschränken.
Anforderungen bestimmen das richtige Konzept
Welches das bessere Konzept zur Bereitstellung operativer Daten für Analysen ist, lässt sich pauschal nicht beantworten, sondern ist von den konkreten Anforderungen abhängig. Können die oben beschriebenen Rahmenbedingungen für den Aufbau eines Data Lake erfüllt werden, bietet sich diese Konzept insbesondere bei den folgen Anforderungen an:
- Zugriff auf originäre Datenstrukturen: Die Bereitstellung von Roh-Daten ist ein Kern-Element des Data Lake-Konzepts. Je nach Historisierungs- und Replizierungskonzept können hier auch Roh-Daten mit einer lange Historie und/oder einzelnen Zustandsänderungen verfügbar gemacht werden. Typische Anwendungsfälle liegen dabei z.B. im Bereich Compliance und Revision.
- Geringer Standardisierungsgrad: Vorteil des Konzeptes ist die hohe Flexibilität bei Abfragen und Analysen auf einer breiten Datenbasis, wie Sie beispielsweise für Fragestellungen im Bereich Data Mining und Data Exploration benötigt wird oder auch für Ad-hoc-Anfragen z.B. im regulatorischen Kontext (QIS, AQR). Für Standard-Abfragen ist das Konzept ebenfalls geeignet, hier hat das klassische Datawarehouse durch die vorherige Transformation der Daten aber ebenfalls gewisse Vorteile.
- Sehr großes Datenvolumen: Die Umsetzung des Data Lake-Konzepts basiert auf dem Einsatz von Big Data-Technologien, die speziell für den Umgang mit sehr großen Datenmengen konzipiert wurden. Neben der hohen Performance über Verteilungsmechanismen, kommen hier auch die Kostenvorteile aus der Verwendbarkeit von Standard-Hardware zum Tragen.
- Neartime-Verfügbarkeit: Die Bereitstellung von Roh-Daten kann aufgrund der fehlenden Transfomationsnotwendigkeiten sehr zeitnah erfolgen. Über spezielle Replizierungsmechanismen ist bedarfsweise ein annähernd zeitlich synchrone Datenversorgung des Data Lake möglich. Hierdurch kann der Data Lake z.B. auch als Datenquelle für ein Online-Banking genutzt werden ohne die Last für die operativen System zu erhöhen.
Das klassische DWH hat weiterhin seine Stärken, wenn der Analysefokus einen definierten Scope hat und häufig wiederkehrende standardisierte Abfragen erfolgen. Ebenso ist es das bevorzugte Konzept, wenn eine konsolidierte Gesamtsicht gefragt ist, die von unterschiedlichen Abnehmern konsistent abgefragt werden muss.
Beide Konzepte lassen sich auch sinnvoll kombinieren. So kann ein Data Lake gut als „Staging Area“ für ein klassisches DWH dienen, wodurch die Roh-Daten nur einmal für unterschiedliche Anforderungen bereitgestellt werden müssen und langfristig zur Verfügung stehen. Gleichzeitig kann man das Zieldatenmodell eines DWH wieder im Data Lake verfügbar machen und dessen konsolidierten Datenhaushalt damit für flexiblere Analysen zur Verfügung stellen.
Ein Data Lake kann somit sehr gut als Ergänzung zu bestehenden DWHs aufgebaut und sukzessive in die existierende Systemlandschaft integriert werden.


Eine Antwort auf “Big Data im Banking: Data Lake statt Data Warehouse?”
Kathage
Super Bericht!