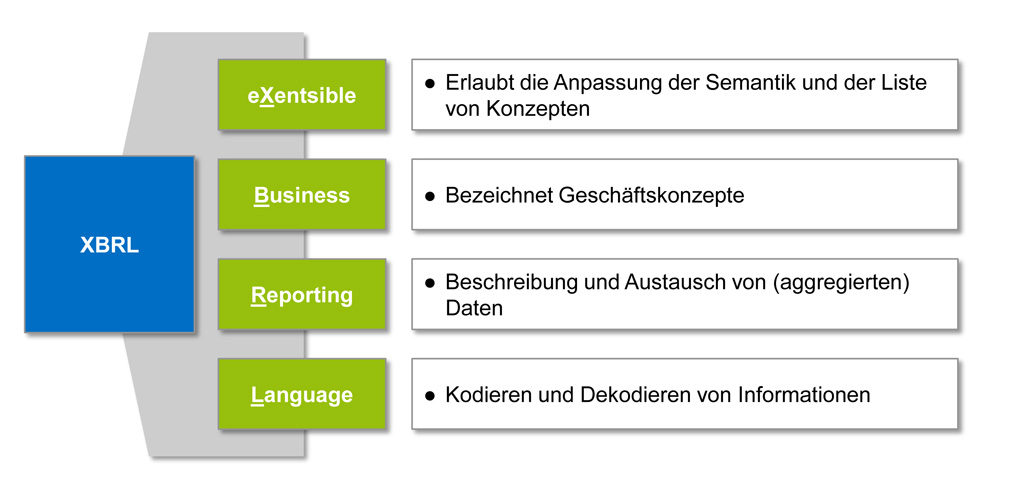
 Abbildung 1: XBRL ist eine technische Sprache für die Beschreibung von Geschäftsdaten
Abbildung 1: XBRL ist eine technische Sprache für die Beschreibung von GeschäftsdatenXBRL selbst ist eine frei verfügbare elektronische Sprache für das „Financial Reporting“ und wird für den Austausch von Informationen von und über Unternehmen verwendet. XBRL bietet einen Standard für die Erstellung, die Verbreitung/Veröffentlichung, Auswertung und den Vergleich solcher Informationen. Über eine Taxonomie werden die verschiedenartigen Elemente, aus denen ein XBRL-Informationspaket bestehen kann und ihre Beziehungen zueinander, definiert (Quelle: www.xbrl.de).
XBRL wiederum basiert auf der Sprache XML (Extensible Markup Language), einer Web-Sprache zur Darstellung hierarchisch strukturierter Daten in Form von Textdateien. XML wird u. a. für den plattform- und implementationsunabhängigen Austausch von Daten zwischen Computersystemen, insbesondere über das Internet, eingesetzt (Quelle: Tim Bray: Extensible Markup Language (XML) 1.0 (Fourth Edition) – Origin and Goals. World Wide Web Consortium, September 2006). In der Taxonomie für die elektronische Meldung wird beispielsweise das erste Feld des COREP Meldebogen C 01.00, in dem das Eigenkapital gemeldet wird, über folgende Ausprägungen genau beschrieben:
- Metric = Amount including transitional provisions
- Base = Own funds
- Main category = Regulatory capital items
- Own funds = Total own funds
 Abbildung 2: XBRL-Code Beispiel für eine COREP Meldung an die Aufsicht
Abbildung 2: XBRL-Code Beispiel für eine COREP Meldung an die AufsichtDas XBRL Format an sich ist der richtige Ansatz, ermöglicht es doch eine einheitliche Darstellung von Geschäftsdaten basierend auf den durch die EBA veröffentlichten Taxonomien. Jedoch stellt gerade die Einhaltung dieser Taxanomien erhebliche Anforderungen an die Software.
Die großen Meldewesen-Softwarehersteller bieten mittlerweile in ihren Produkten die Erstellung von XBRL-Codes aus den Meldedaten an. Andere Anbieter stellen umfangreiche Engines zur Erzeugung von XBRL-Codes zur Verfügung, die in die bestehende Softwarelandschaft integriert werden muss.
Für kleine und mittlere Finanzinstitute kann die Anschaffung einer umfassenden Meldewesensoftware schnell zu einer signifikanten Investition führen. Aber auch große Institute, welche bereits über Lösungen verfügen und „nur noch“ die XBRL-Code Erzeugung benötigen, müssen mit größeren Investitionen rechnen. Manchmal genügt jedoch eine einfache Aufbereitung der Daten aus einer bestehenden Anwendung oder die manuellen Erfassung direkt in den Meldebögen und ein Tool, welches die Meldung ohne Aufwand direkt in den XBRL-Code transformiert. Und da sich die Taxonomie mehrmals jährlich ändern kann (aktuell beobachten wir bis zu drei Anpassungen seitens der EBA pro Jahr, die sowohl kleinere Fehlerkorrekturen als auch umfangreiche Erweiterungen für neue Bögen enthalten), ist es sinnvoll diese Transformation gut zu kapseln und den Änderungsaufwand an einen Anbieter von Standardsoftware auszulagern.
Solch schlanke Lösungen, welche sich auf die reine Darstellung der Meldedaten in den Meldebögen, die Plausibilisierung nach den Regeln der EBA und die Erzeugung des XBRL-Codes beschränken, sind jedoch am Markt nicht leicht zu finden.
Jedoch, es gibt sie! Einfache Excel-basierte Anwendungen, welche die Meldedaten übersichtlich in Form der Meldebögen darstellen und mit Hilfe von Excel-Addins den notwendigen XBRL-Code erzeugen können.
 Abbildung 3: Eine auf Microsoft Excel basierte Anwendung zur Erzeugung der Meldung mit XBRL
Abbildung 3: Eine auf Microsoft Excel basierte Anwendung zur Erzeugung der Meldung mit XBRLDiese Anwendungen bestehen im Wesentlichen aus einer Excel-Vorlage, welche die offiziellen Meldebögen übersichtlich darstellen. Sie bieten einfache Funktionen zum Einladen vorbereiteter Meldedaten, welche mittels eines für den Kunden individuell anpassbaren Konverters in ein simples Format überführt werden. Sie generieren alle notwendigen Meldebögen (z.B. für Eigenkapitalanforderungen, Kreditrisiken (KSA und IRBA), Marktrisiken, Leverage Ratio, Großkredite, Liquidität, geografischer Aufriss, usw.) auf Basis der angelieferten oder manuell erfassten Daten. Die Meldebögen können noch vor der eigentlich XBRL-Code Erzeugung nach den offiziellen Regeln der EBA plausibilisiert werden, um frühzeitig Inkonsistenzen in der Meldung zu erkennen.

